Crea tu propia plataforma de ChatGPT con Open WebUI
Descubre cómo crear tu propio ChatGPT con Open WebUI. Ahorra dinero o incluso hazlo gratis y con total control. Haz marketing con el poder de la IA.

Si bien la inteligencia artificial generativa está al alcance de cualquier persona en el mundo, gracias a modelos abiertos (“open source”) como Llama de Meta (disponible en Whatsapp, Instagram, Facebook Messenger o en MetaAI) y versiones gratuitas de soluciones comerciales líderes como ChatGPT de OpenAI, Claude de Anthropic y Gemini de Google; es posible que si las usas de manera intensiva, te encuentres con límites en tu experiencia.
En el caso de ChatGPT, la versión gratuita tiene un límite de mensajes durante una ventana de tres horas, superado dicho límite, volverás a la versión 3.5 y tendrás que esperar un tiempo para tener de vuelta las funciones del modelo más avanzado. Por su parte, los modelos de Meta también limitan el consumo de las soluciones más avanzadas como Llama 3.1, después de cierto número de mensajes, se limitará tu interacción a modelos inferiores. El mismo caso aplica para Claude y Gemini respectivamente.
Estas limitaciones probablemente te hagan plantearte pagar por alguna de estas herramientas y quizás considerar la versión de pago de ChatGTP, al fin y al cabo, la solución de OpenAi ofrece las mejores funcionalidades hasta el momento.
¿Pero te diste cuenta del costo? ¡20 dólares mensuales! Y ni hablemos de pagar para habilitar a todo tu equipo de trabajo. La licencia mensual para equipos está en 25 dólares por persona.
Para algunos pagar un servicio tan costoso está fuera de consideración. ¿Pero qué te parecería si te dijera que puedes reducir el costo de GPT-4o a mínimo 5 dólares mensuales? ¿Y si además te cuento que puedes correr modelos de inteligencia artificial localmente en tu computador?
En este artículo, te voy a contar paso a paso cómo consumir la API de OpenAI para acceder a modelos como ChatGPT 4o, y además, te explicaré cómo correr modelos LLM (Large Language Model, o Modelo de Lenguaje Grande) “open source” en tu computador de forma gratuita, todo esto sobre una interfaz muy parecida a la de ChatGPT, incluso con unas funcionalidades adicionales.
Este tutorial puedes seguirlo para habilitar tu propio entorno de IA generativa para uso personal exclusivo o incluso para que en tu empresa o equipo de trabajo se acceda a la misma herramienta.
¿Cuáles son las ventajas de tener tu propio entorno de IA generativa?
- Control en el costo de uso de los modelos: Control sobre lo que planeas pagar de una forma más granular en el caso que consumas APIs comerciales como la de OpenAI.
- Seguridad y privacidad en el uso de la información: las políticas sobre las APIs de IA generativa, son diferentes a las que utilizan las soluciones comerciales como ChatGPT. Mientras que en la solución comercial tu información está expuesta y puede ser usada para entrenar a los modelos, las APIs ofrecen un mayor nivel de privacidad, esto depende de las políticas del servicio. En el caso de la API de OpenAI, la información suministrada por los prompts del usuario no son usadas para entrenar a los modelos. Puedes conocer más aquí.
- Control sobre el uso de la IA generativa en tu compañía o equipo de trabajo: Puedes controlar los usos de la IA imponiendo restricciones de uso, incluso limitando ciertas funcionalidades.
- Amplio catálogo de modelos: Tienes acceso a más modelos de inteligencia artificial desde un solo lugar y esto te garantiza poder comparar respuestas a tus prompts y quedarte con la mejor solución de acuerdo a tus necesidades.
- Una solución administrada por ti: Puedes desplegar este entorno en un servidor, abrir los puertos de tu servicio de internet o habilitar la conexión en una red LAN para que tu empresa o equipo de trabajo tenga su propio sistema de inteligencia artificial ajustado a tus políticas empresariales y con la certeza que la información confidencial de la compañía y sus clientes no va a alimentar el aprendizaje de los modelos de inteligencia artificial.
¿Cómo está construido este tutorial?
Este tutorial está dividido en tres partes, la primera parte es esencial para lograr usar la API de OpenAI y correr modelos localmente (es obligatoria), la segunda parte se centrará en el consumo de la API y la configuración de OpenAI Platform, y finalmente, la tercera parte te explicará cómo usar Ollama para ejecutar modelos LLM localmente en tu computador.
Puedes saltarte la parte 2 o 3 dependiendo de tus necesidades, también puedes seguir todo el tutorial y finalizar con ambas funcionalidades listas para que expandas todas tus posibilidades con la IA generativa.
Requisitos para seguir este tutorial
Es importante que tengas presente que este tutorial requiere que instales varias aplicaciones en tu computador y que adicionalmente tengas que correr comandos en la terminal. ¡Que esto no te asuste! Todo lo que vamos a hacer no dañará tu dispositivo y es fácilmente desinstalable.
Requerimientos generales:
- Descargar e instalar Docker (más adelante te explico qué es y para qué funciona). Puedes descargarlo aquí.
- Instalar a través de Docker una aplicación llamada Open WebUI (más adelante te explico qué es, para qué funciona y cómo instalarla).
Requerimientos para utilizar la API de OpenAI:
- Una tarjeta de crédito con al menos 5 dólares de cupo. ¿Por qué 5? Porque es lo mínimo que OpenAI permite comprometer para usar su API.
- La creación de una cuenta en OpenAI Platform.
- Tener un computador personal con suficiente espacio de almacenamiento (al menos 10gb), por lo menos 8gb de ram (puede ser menos, pero podrías quedarte corto) y una conexión a internet estable y constante ya que vamos a estar conectados a OpenAI.
Requerimientos para correr modelos de inteligencia artificial localmente:
Debido a que los modelos de inteligencia artificial correrán sobre los recursos de tu computador, en este caso debes tener una máquina algo más potente. Si no la tienes, puedes quedarte solo con la solución de consumir la API de OpenAI. A continuación los requerimientos que debe cubrir tu computador:
- Almacenamiento: Al menos 50gb de almacenamiento (ya que vas a descargar los modelos), no necesitaremos tanto para este tutorial, pero si planeas probar varios modelos vas a necesitar esta capacidad.
- Procesador: Al menos generación 11 de intel, Zen4 de AMD o un Mac con chip M1,
- Ram: Al menos 16gb de ram DDR4 (puedes usar menos, pero la experiencia puede afectarse).
- Tarjeta de video: Aunque no es obligatorio, una tarjeta de video o GPU, puede mejorar la experiencia al facilitar correr modelos con muchos más billones de parámetros. Puedes ver aquí los requerimientos oficiales para las tarjetas de video.
Parte 1: Configurar las herramientas para consumir la API de OpenAI y correr modelos localmente
En esta primera parte, te contaré qué es Docker y te hablaré de la solución de Open WebUI. Ambas aplicaciones deberán instalarse en tu computador.
¿Qué es Docker?
Docker es una plataforma para desarrolladores de aplicaciones que permite crear, desplegar y ejecutar contenedores, estos son una especie de empaquetado que incluye todo lo que una aplicación requiere para funcionar.
Docker en Windows o Mac ejecuta una máquina virtual de Linux sobre la que corren los contenedores y en ellos hay una serie de elementos esenciales para que funcione la aplicación.
Los contenedores se generan a partir de una imagen que previamente ha sido construida con todo lo necesario para que corra la aplicación. Estas imágenes se descargan y se ejecutan para crear los contenedores.
Docker puede controlarse a través de la terminal de tu sistema operativo o también desde una aplicación desktop llamada Docker Desktop que viene dentro del mismo paquete de instalación y es la que usaremos en este tutorial.
¿Por qué necesitamos Docker?
La aplicación que necesitamos correr para emular un entorno o interfaz parecida a la de ChatGPT se llama Open WebUI, es una solución de código abierto que ha sido distribuida por sus creadores a través de Docker para que sea desplegada (usada) bien sea localmente o en servidores. De ambas formas la herramienta es accesible a través de un explorador web como Chrome, Firefox, Edge o cualquier otro.
Aunque no es obligatorio tener una interfaz de estas características para consumir la API de OpenAI o correr modelos localmente, facilita mucho la interacción y permitirá que cualquier usuario (en este caso tú o alguien de tu equipo) interactúe con los modelos de forma sencilla.
Instalando docker
Accede a este link y en la página principal descarga la última versión de la aplicación para tu sistema operativo.
Una vez descargada, ejecuta el instalador y sigue el paso a paso, no deshabilites ninguna opción y culmina la instalación. Te pedirá que reinicies tu computador, recuerda volver a abrir este tutorial cuando se termine el reinicio.
Descargar la imagen de Open WebUI
Ejecuta la aplicación Docker Desktop y ahí asegúrate de estar sobre la pestaña de “Containers” de la barra lateral izquierda. Una vez ahí, en la esquina inferior derecha verás una opción que dice terminal, al hacerle clic te preguntará si deseas habilitar la terminal, dale en “enable terminal”.
Una vez en la terminal vas a correr uno de los siguientes comandos, cópialo y pégalo:
Si tienes un computador sin tarjeta de video dedicada (como un portátil) o si eres usuario de Mac:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainSi tienes una tarjeta de video nvidia en tu computador y planeas correr modelos localmente:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cudaPuedes consultar aquí más comandos de instalación de Open WebUI dependiendo de tus necesidades.
Este es el único comando (código) que deberás correr en la terminal así que si estás perdido y es tu primera vez haciendo algo así, guíate por este gif:
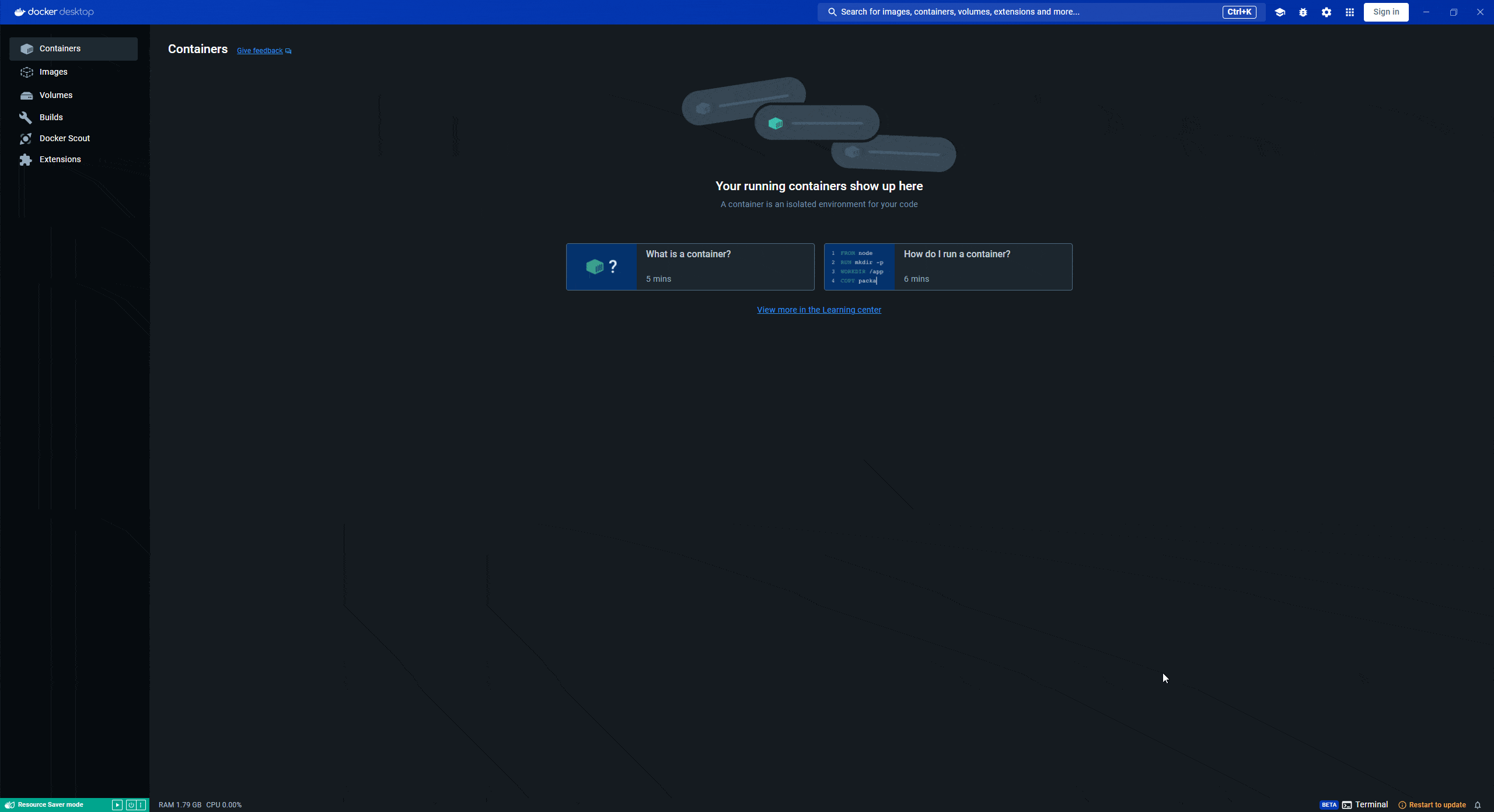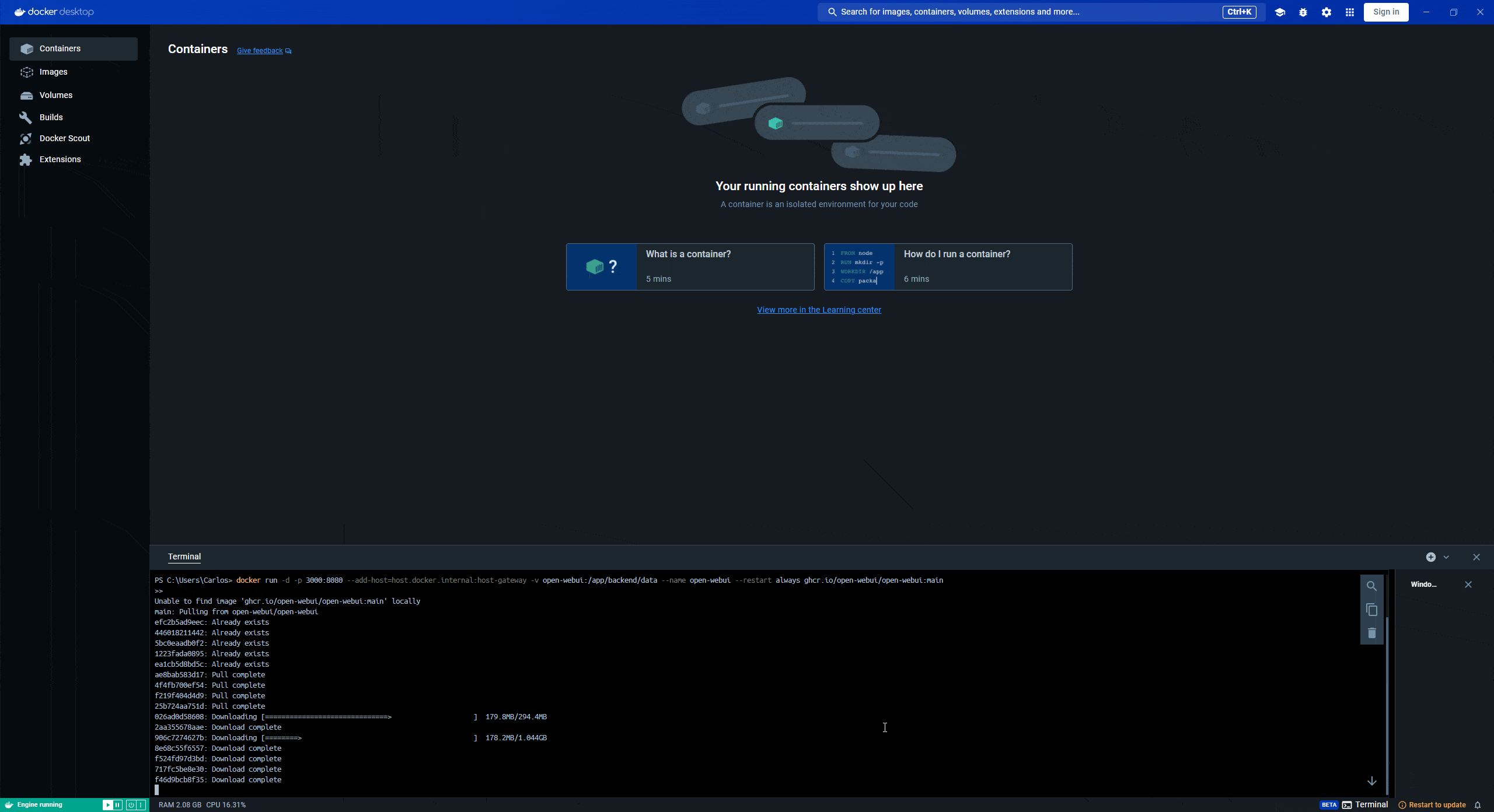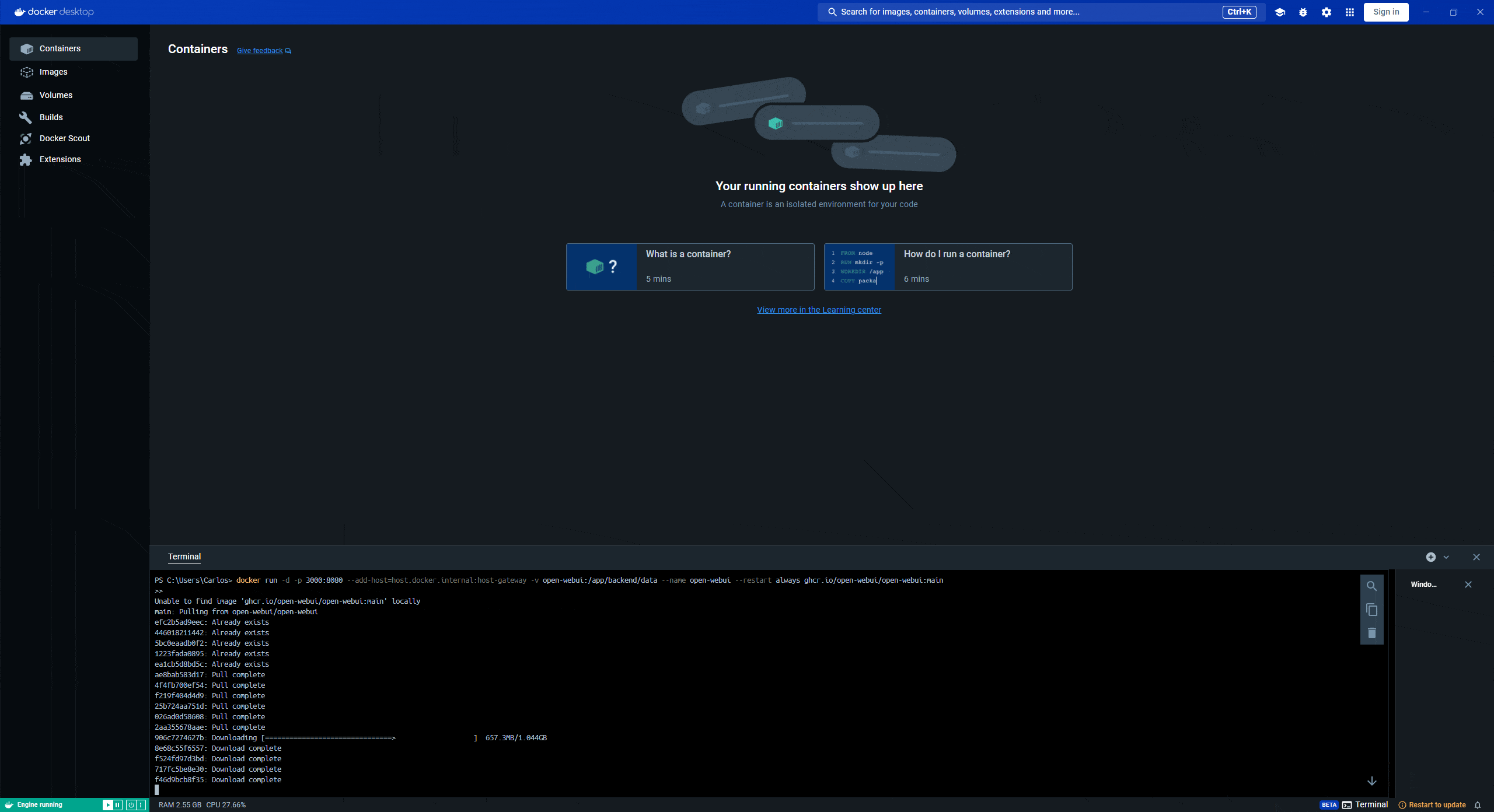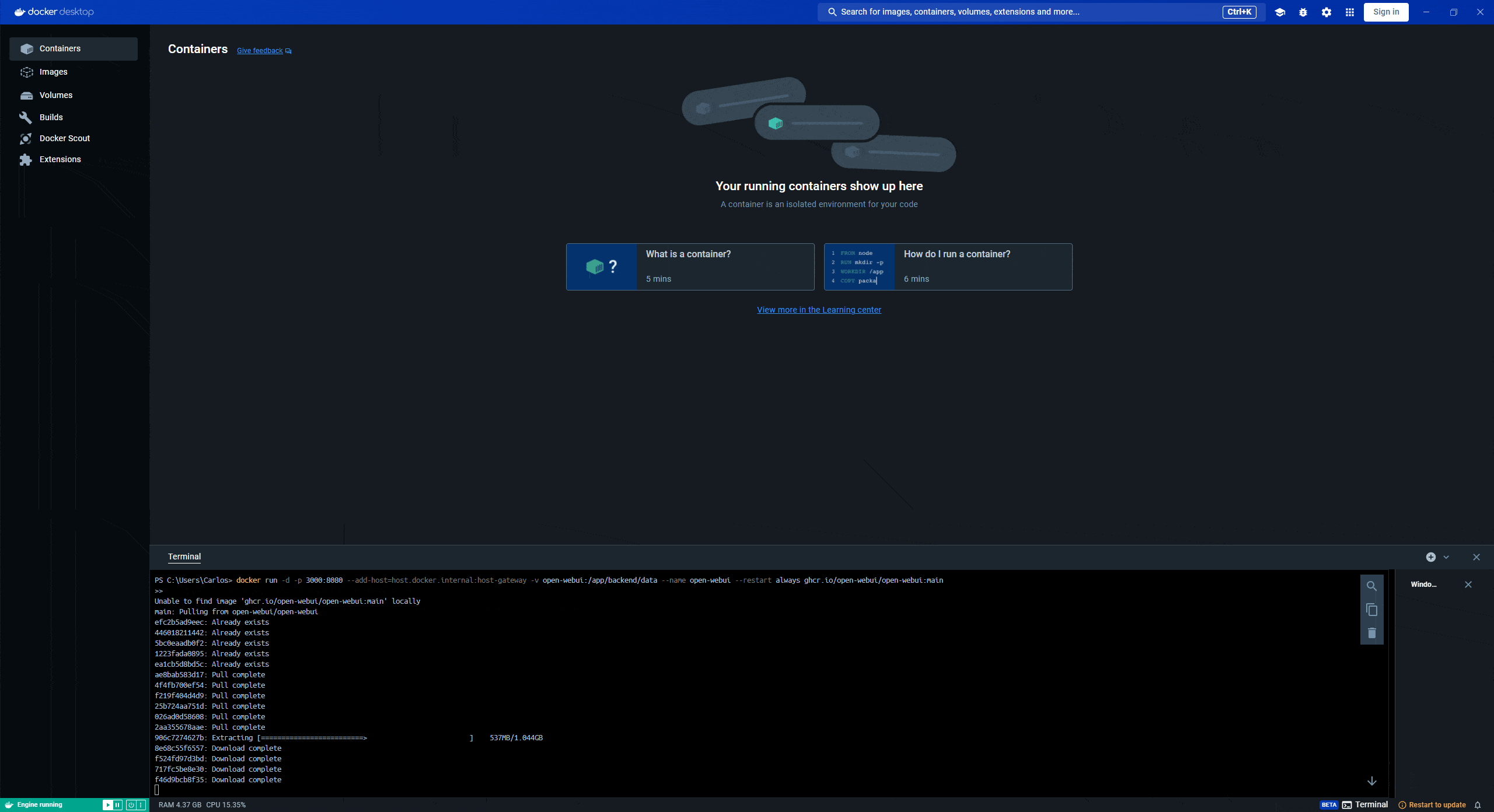
Permite que el comando termine de ejecutarse y el resultado diga lo siguiente:
Status: Downloaded newer image for ghcr.io/open-webui/open-webui:mainSi todo salió adecuadamente según el paso anterior, deberás ver en la pestaña que hay contenedor corriendo con el nombre “open-webui” y a la derecha de las opciones verás una columna que dice “ports” y la indicación que la aplicación está corriendo en el puerto 3000:8080. Esto quiere decir que ya la aplicación está disponible en:
http://localhost:3000/Puedes abrir esta dirección web en tu navegador de preferencia como Google Chrome. “localhost” significa que está corriendo localmente en tu máquina y “:3000” que lo hace sobre ese puerto.
Al abrir esta dirección verás por primera vez un cuadro de inicio de sesión, sobre el que deberás crear tu usuario, el primer usuario creado será el súper administrador de la aplicación, así que ten en cuenta esto para crearlo adecuadamente.
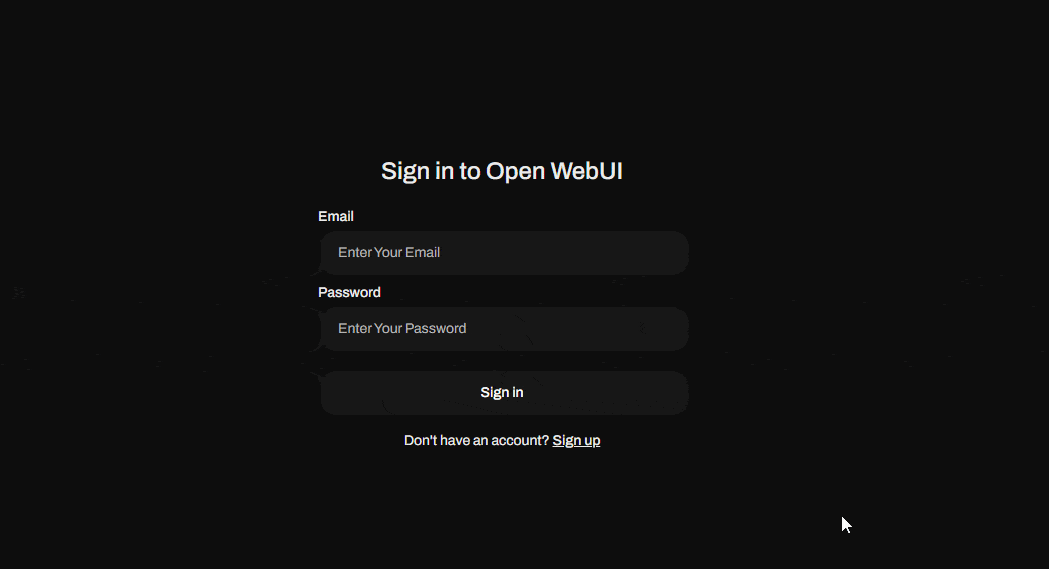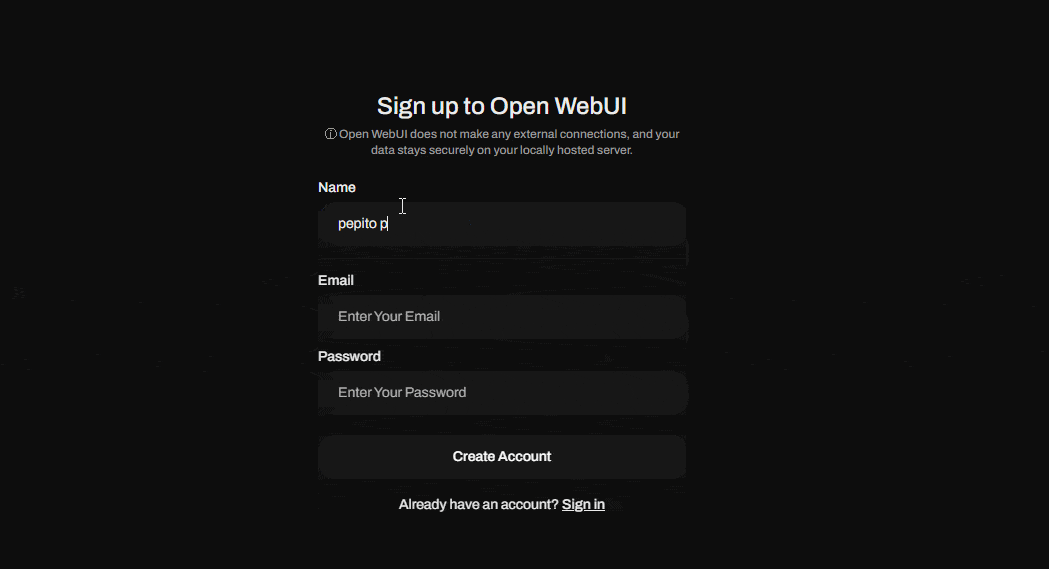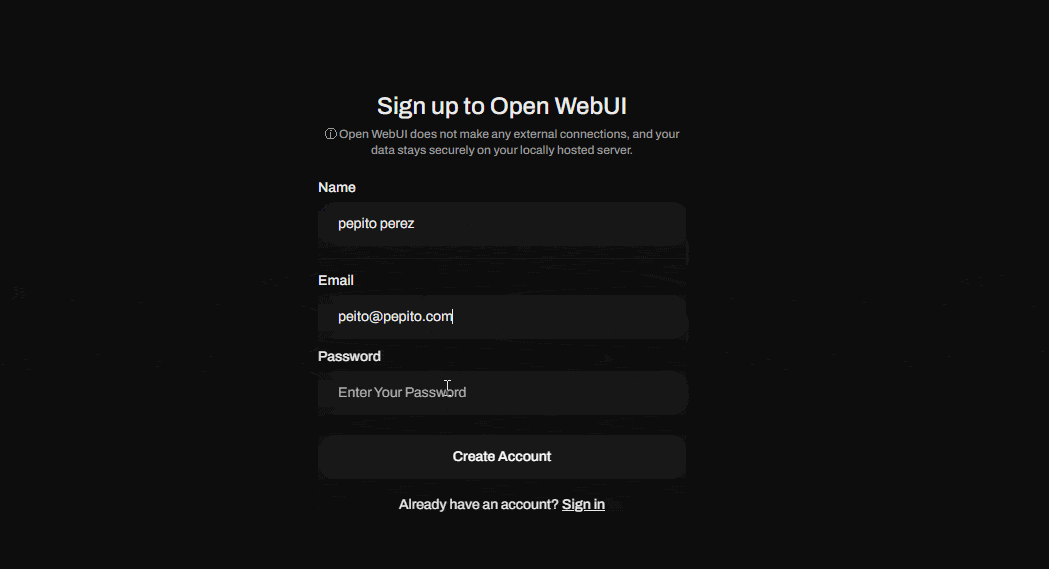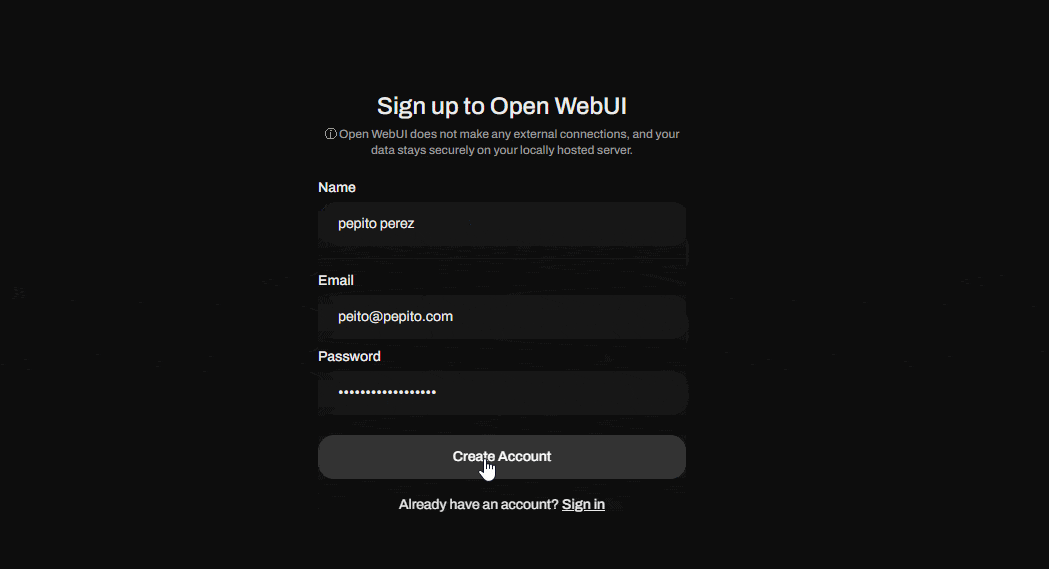
Ahora que ya has creado tu usuario súper admin, procede a hacer “sign in” (iniciar sesión). ¡Voilà! Ya tienes tu propio ambiente o interfaz de IA generativa para correr modelos LLM.
Sin embargo, aún no hay mucho que puedas hacer aquí, no tienes configurada ni tu API de OpenAI ni tampoco tienes algún modelo LLM instalado localmente. Es el momento de pasar a la parte 2 o 3 de este tutorial de acuerdo a la funcionalidad que quieras tener.
Parte 2: Usando la API de OpenAI desde Open WebUI
En esta segunda parte aprenderás cómo conectarte a los servicios de OpenAI para consumir sus modelos desde tu interfaz de Open WebUI, con esto podrás tener casi todas las mismas funcionalidades de ChatGPT a un mejor precio y con mayor control.
¿Qué es una API?
Antes de seguir con el paso a paso, es importante que abordemos la cuestión de qué es una API. La palabra API significa “Application Programming Interface” (Interfaz de Programación de Aplicaciones). Básicamente tenemos que obtener de OpenAI una clave que se usa en una dirección web (en un endpoint de una API) en la cual existe un conjunto de reglas y definiciones que permiten a varias aplicaciones o servicios conectarse entre sí. En nuestro caso, nos conectaremos a OpenAI desde nuestra interfaz de Open WebUI.
¿Cómo configurar tu cuenta en OpenAI platform?
Para esto debes dirigirte a OpenAI platform, ahí en la esquina superior derecha verás la opción para registrarte. Crea una cuenta con tus datos y una vez logueado, dirígete a settings y ahí a billing.
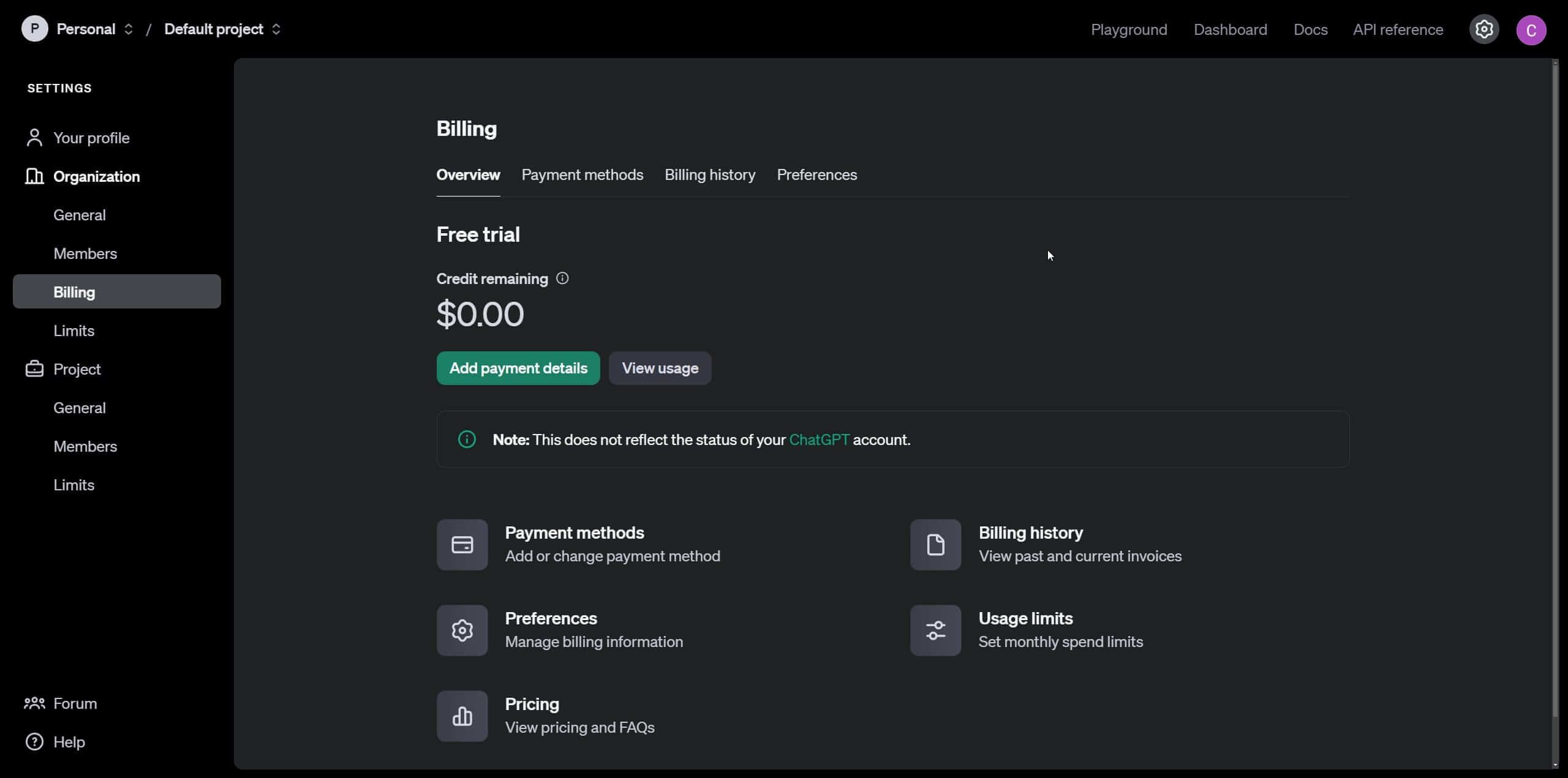
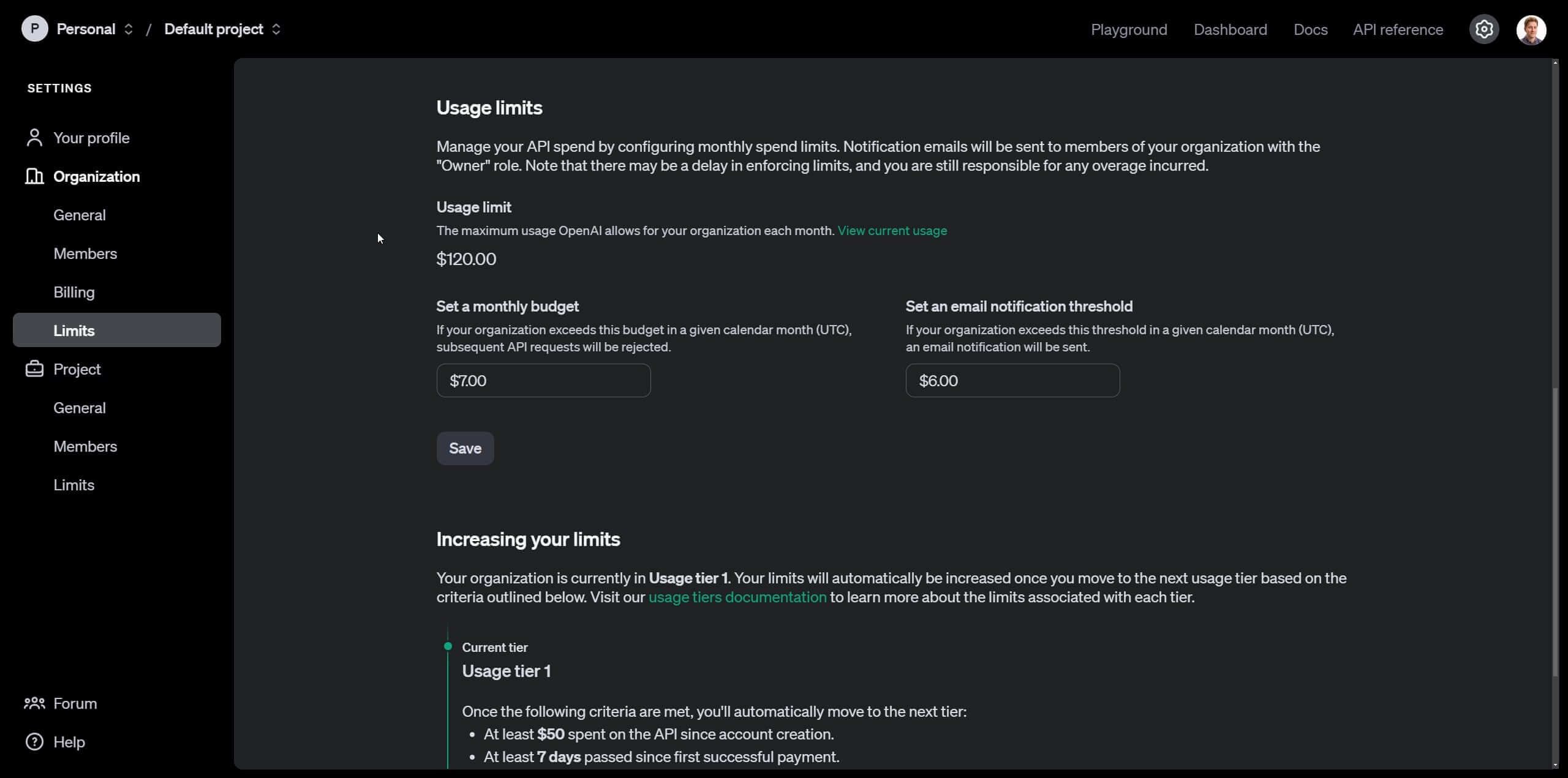
Deberás ingresar una tarjeta de crédito y configurar el monto inicial de tu cuenta, para efectos de este tutorial dejaremos únicamente 5 dólares. Acto seguido, dirígete a “limits” en las opciones de la barra lateral. Ahí podrás establecer un monto máximo a partir del cual se desactivarán las peticiones a la api de OpenAI para no pasarte del presupuesto, y además, podrás establecer un valor intermedio para que seas notificado vía correo si estás acercándote al límite.
¿Cómo obtener una API key o secret key para usar la API de OpenAI?
Completado el setup del cobro por uso de la API, dirígete al dashboard en la opción de la barra superior y ahí pasa a la sección de Api Keys.
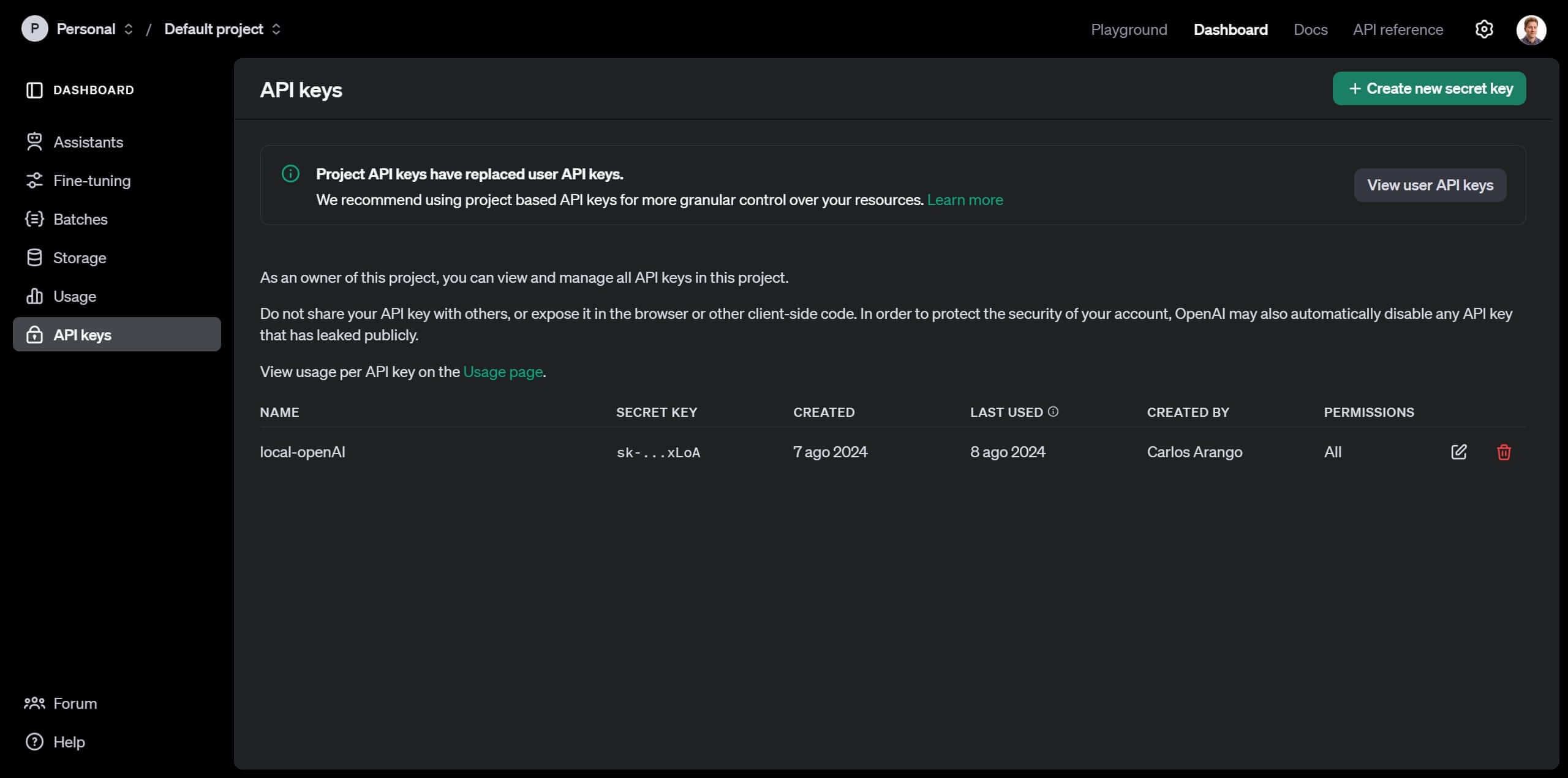
Una vez ahí, crearemos una nueva “secret key”, la que funcionará como clave para que OpenAI relacione el consumo que haremos de su API con nuestra cuenta. Dale click en “Create new secret key”, escribe un nombre y deja todas la opciones por default.
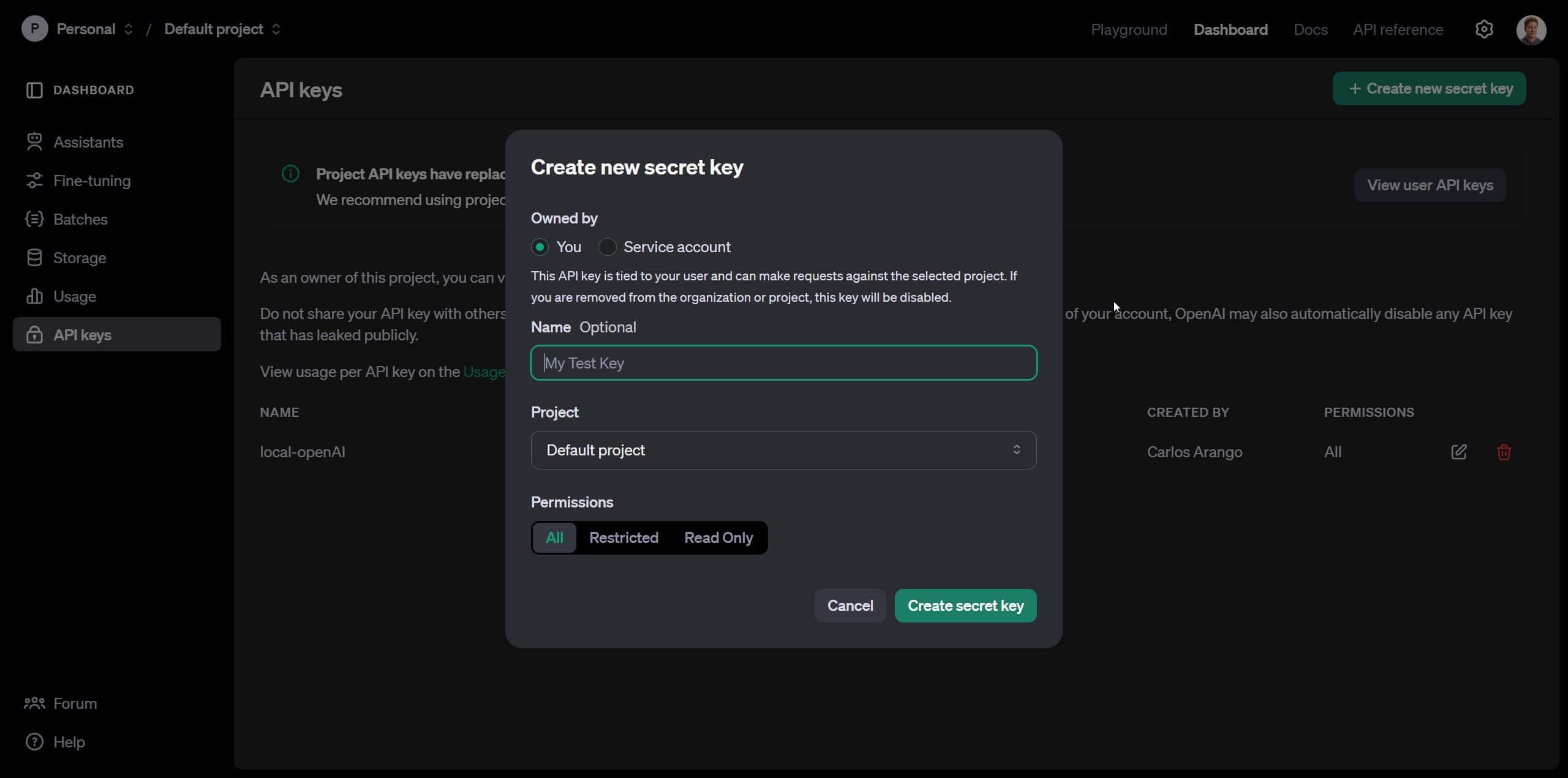
Una vez creada, verás un popup que dice “Save your key”, cópiala y pégala en algún lugar seguro donde solo tú tengas acceso. Las secret keys son privadas y no debes compartirlas.
¿Cómo usar la API de OpenAI desde Open WebUI?
Ahora con la cuenta lista en OpenAI Platform y con la “secret key”, podemos volver a: http://localhost:3000/ donde está corriendo Open WebUI. Ahí te dirigirás a la esquina superior derecha, debes dar click en el icono del usuario, luego en “settings > admin settings > connections”. Sobre esta opción asegúrate de activar “OpenAI Api” y en el campo de la derecha copiar tu “secret key”
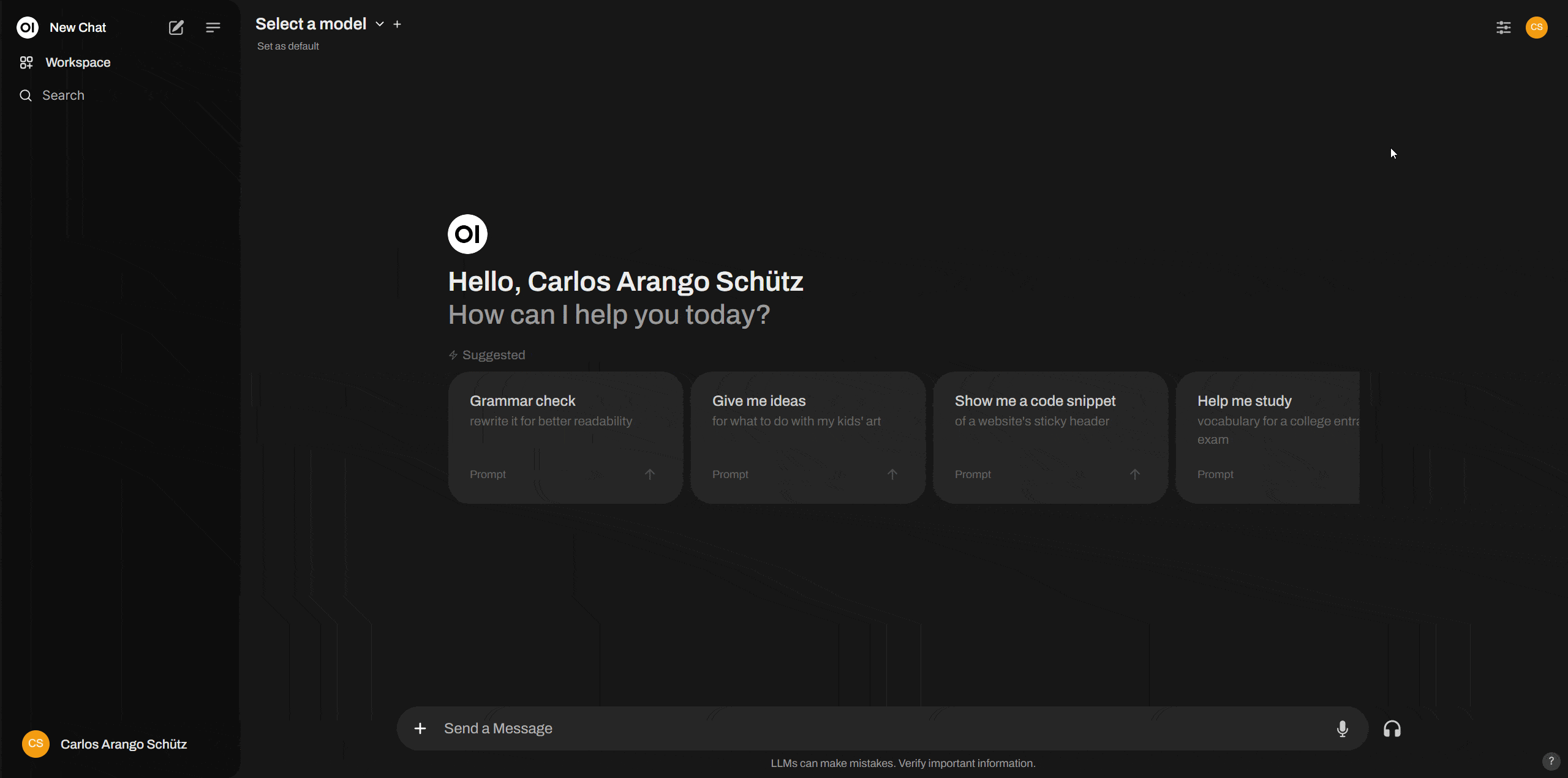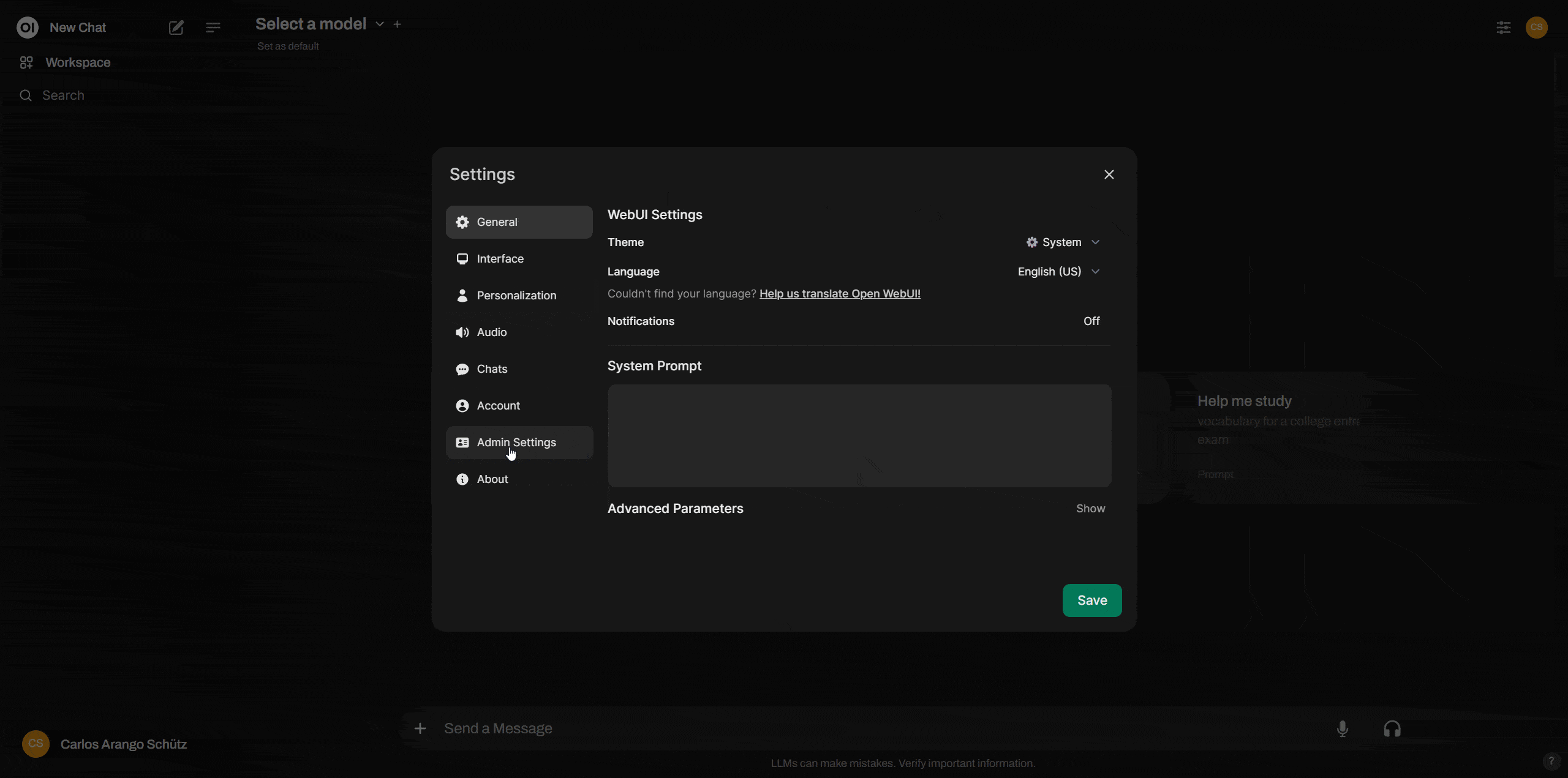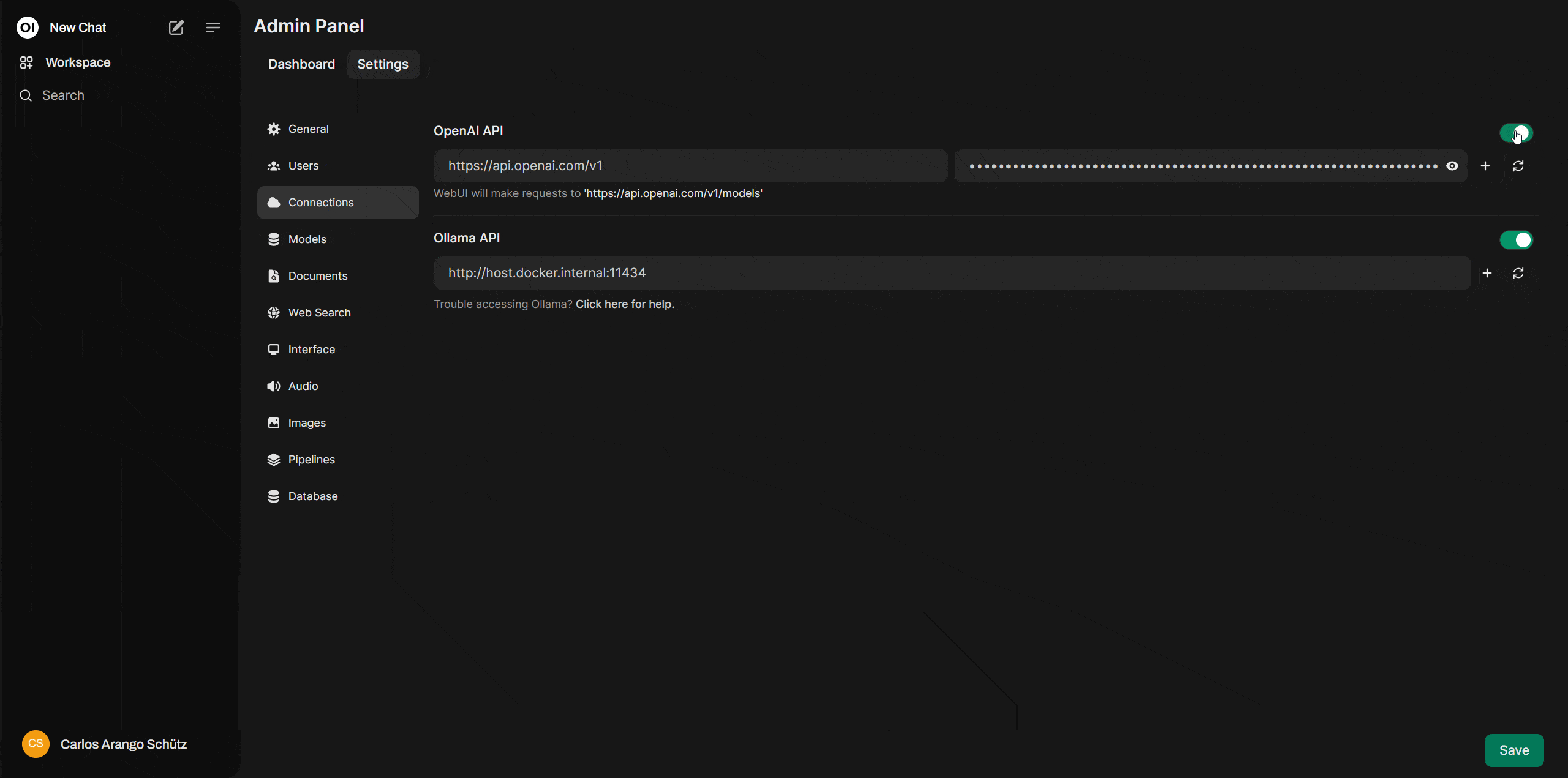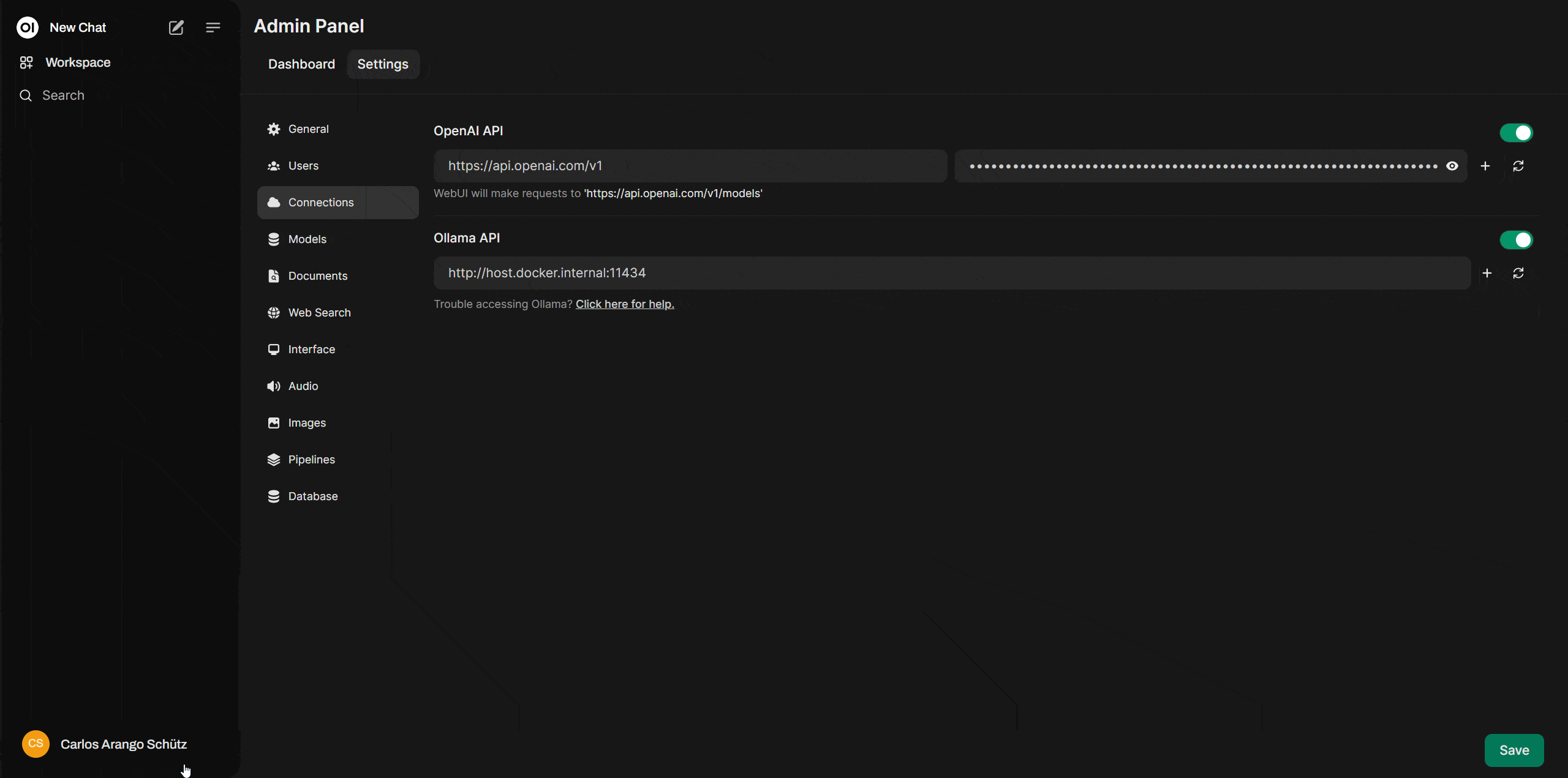
Y listo, ahora ya tienes tu propio ChatGPT corriendo sobre una interfaz de ia generativa propia y con muchas de las funcionalidades que existen en la versión actual de ChatGPT pero con un precio mucho más asequible.
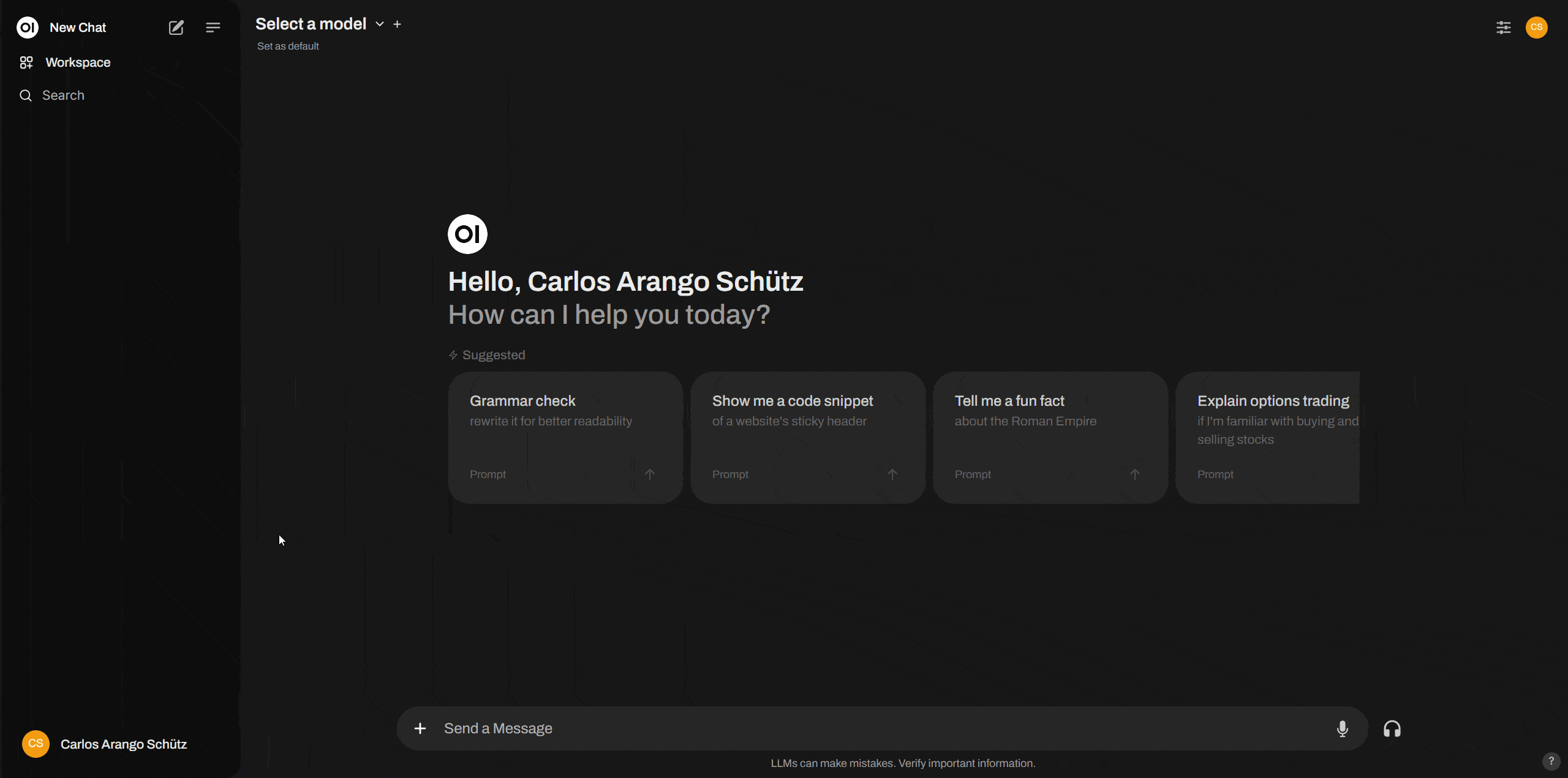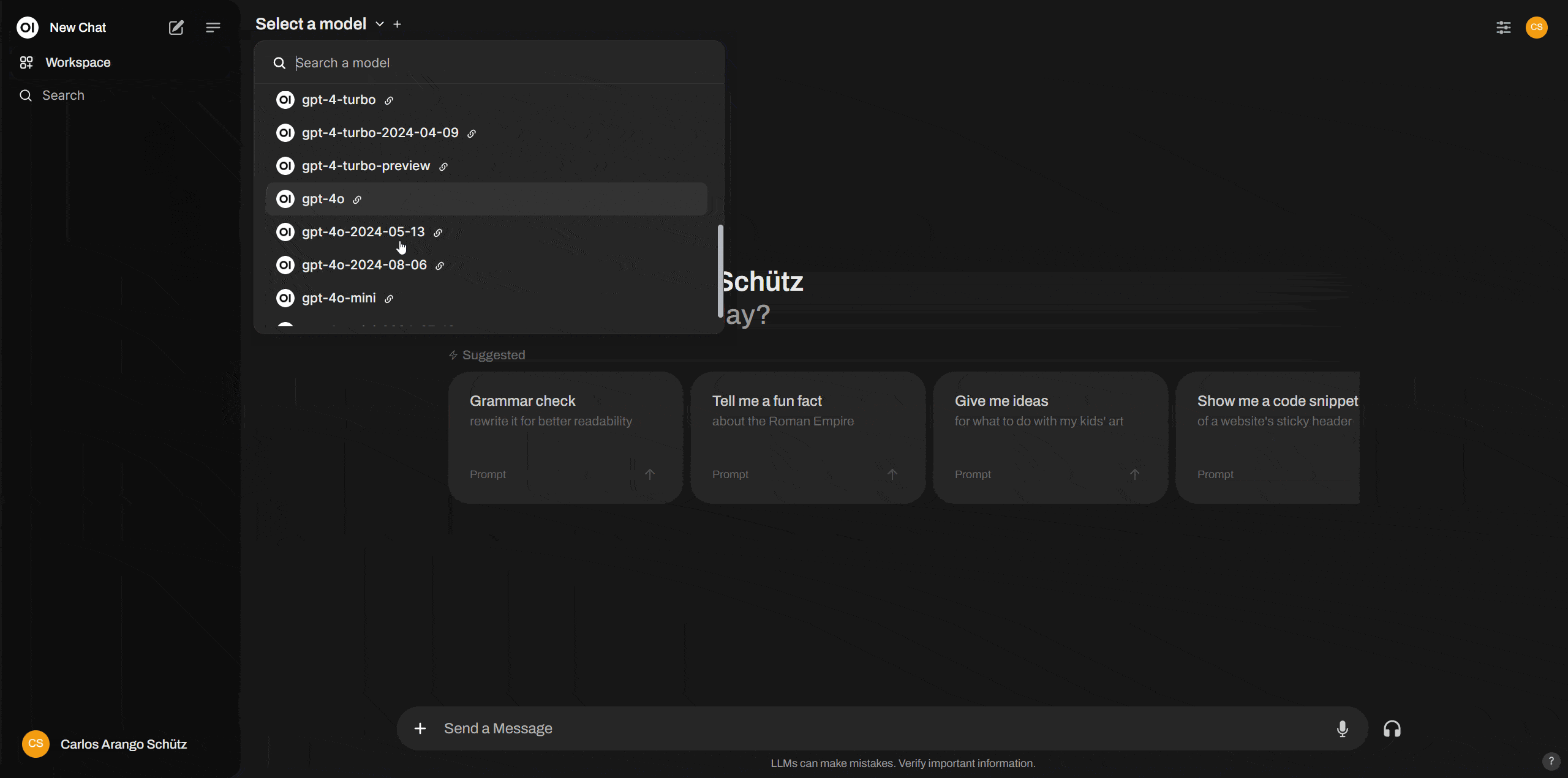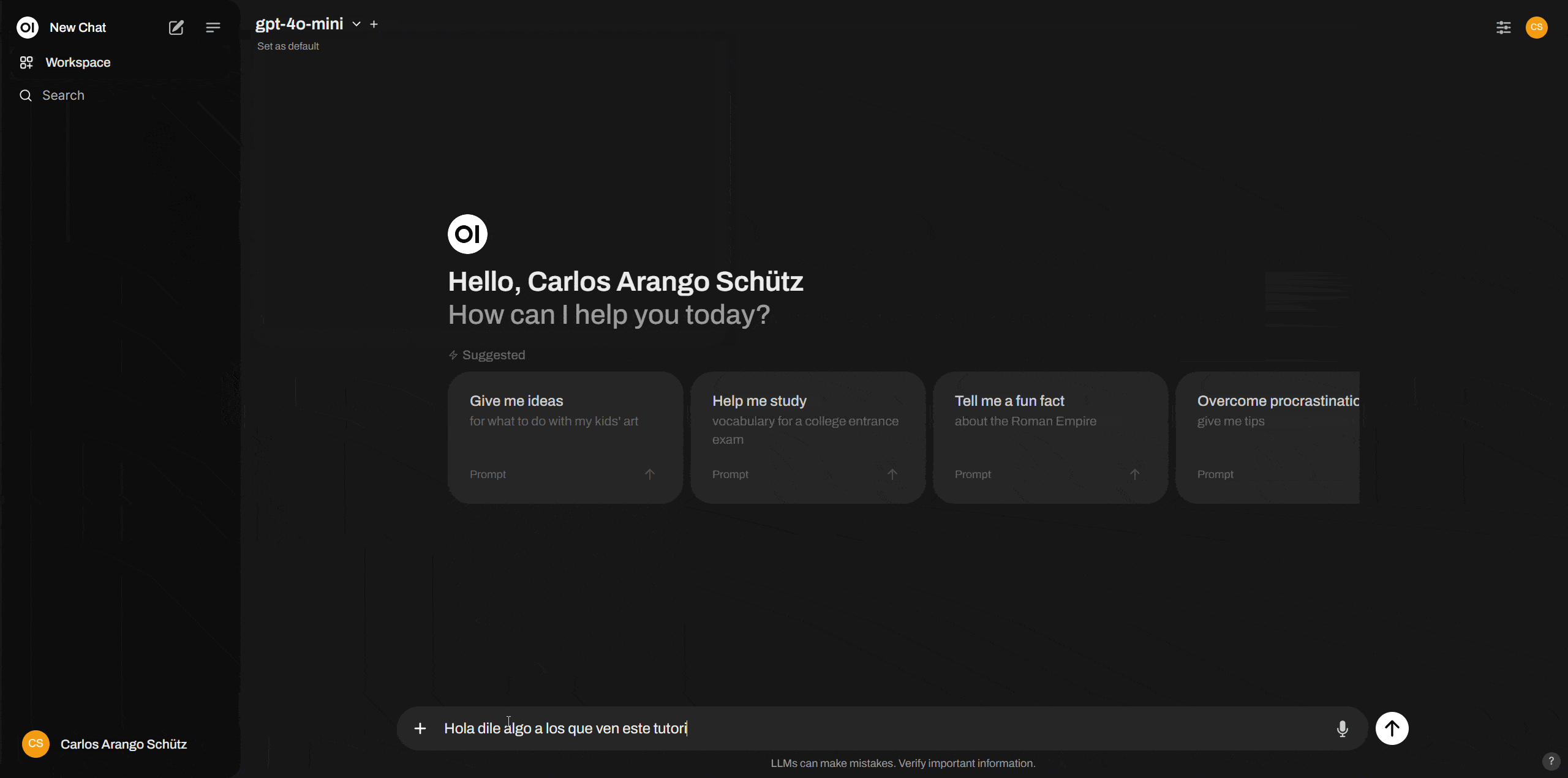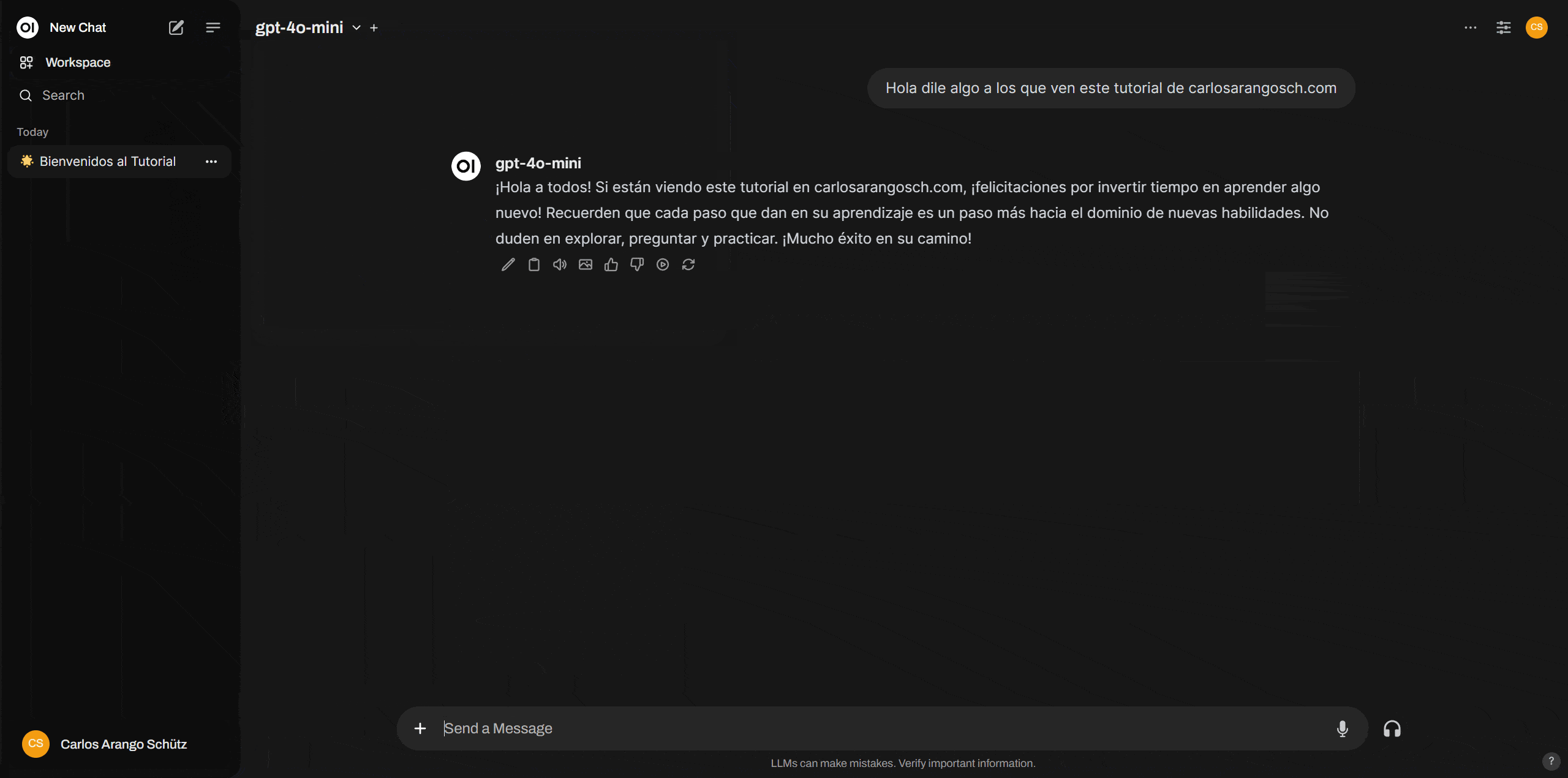
Ahora en la esquina superior izquierda de Open WebUI haz click en “new chat”, justo al lado verás la opción “select a model”, una vez hagas click ahí verás todas las opciones que te da Open AI. Cada uno de los modelos tiene costos de uso diferentes, siendo gpt-4o-mini el más eficiente y económico de todos los modelos. Es el que te recomiendo utilizar para tareas ligeras y cuando necesites todo el poder de la IA, utiliza gpt-4o.
¿Cómo generar imágenes usando Open WebUI y Dall-E 3?
Si has seguido todos los pasos hasta aquí, verás que eres capaz de chatear con los modelos de OpenAI, sin embargo, la generación de imágenes no está habilitada. Para solucionar esto, dirígete a “settings > admin settings > images” ahí selecciona en “Image Generation Engine” OpenAI (Dall-E) y habilita la opción de “Image Generation (Experimental)” poniéndola en ON. Verifica que bajo estas opciones aparezca tu “secret key” de OpenAI.
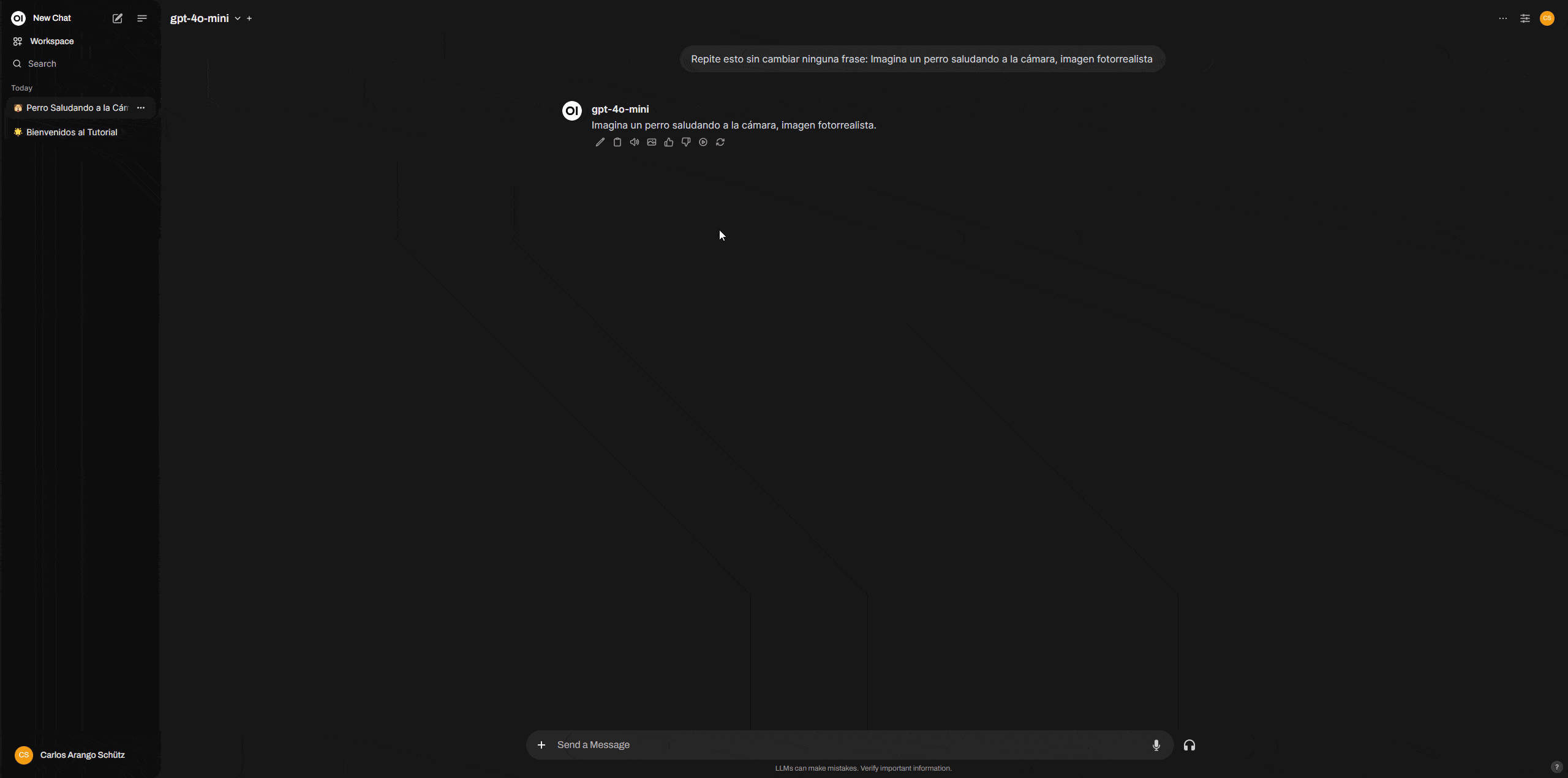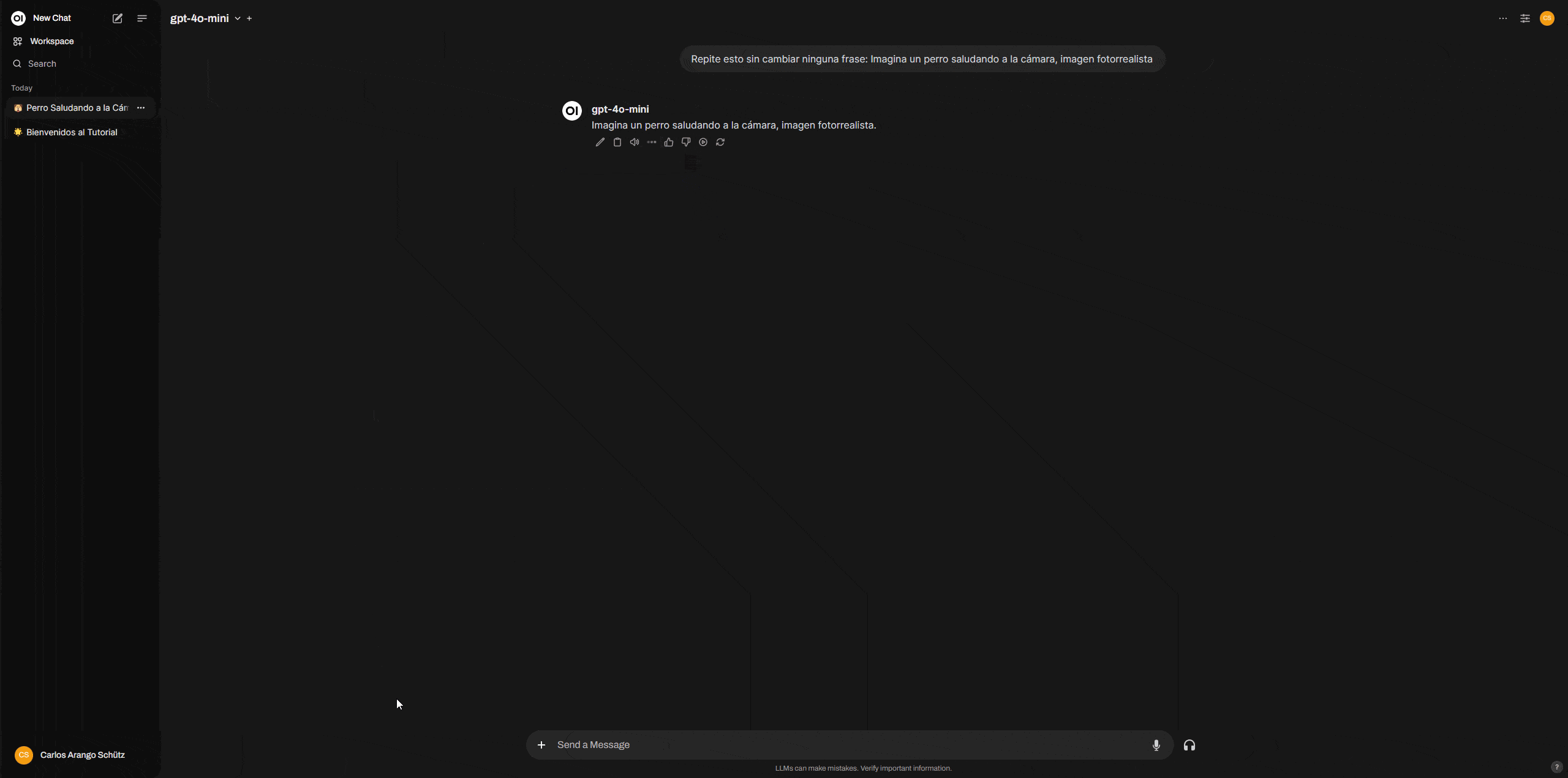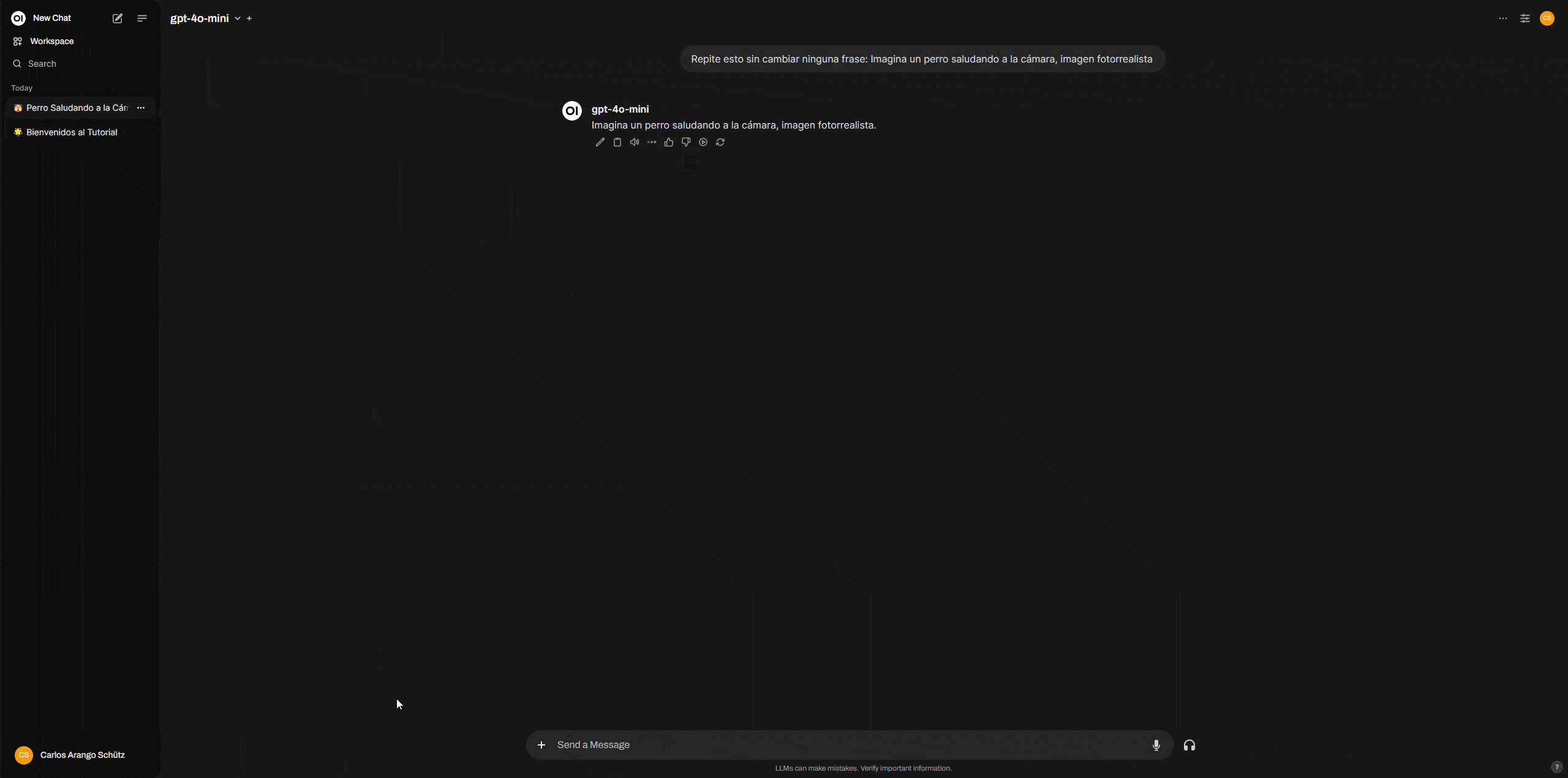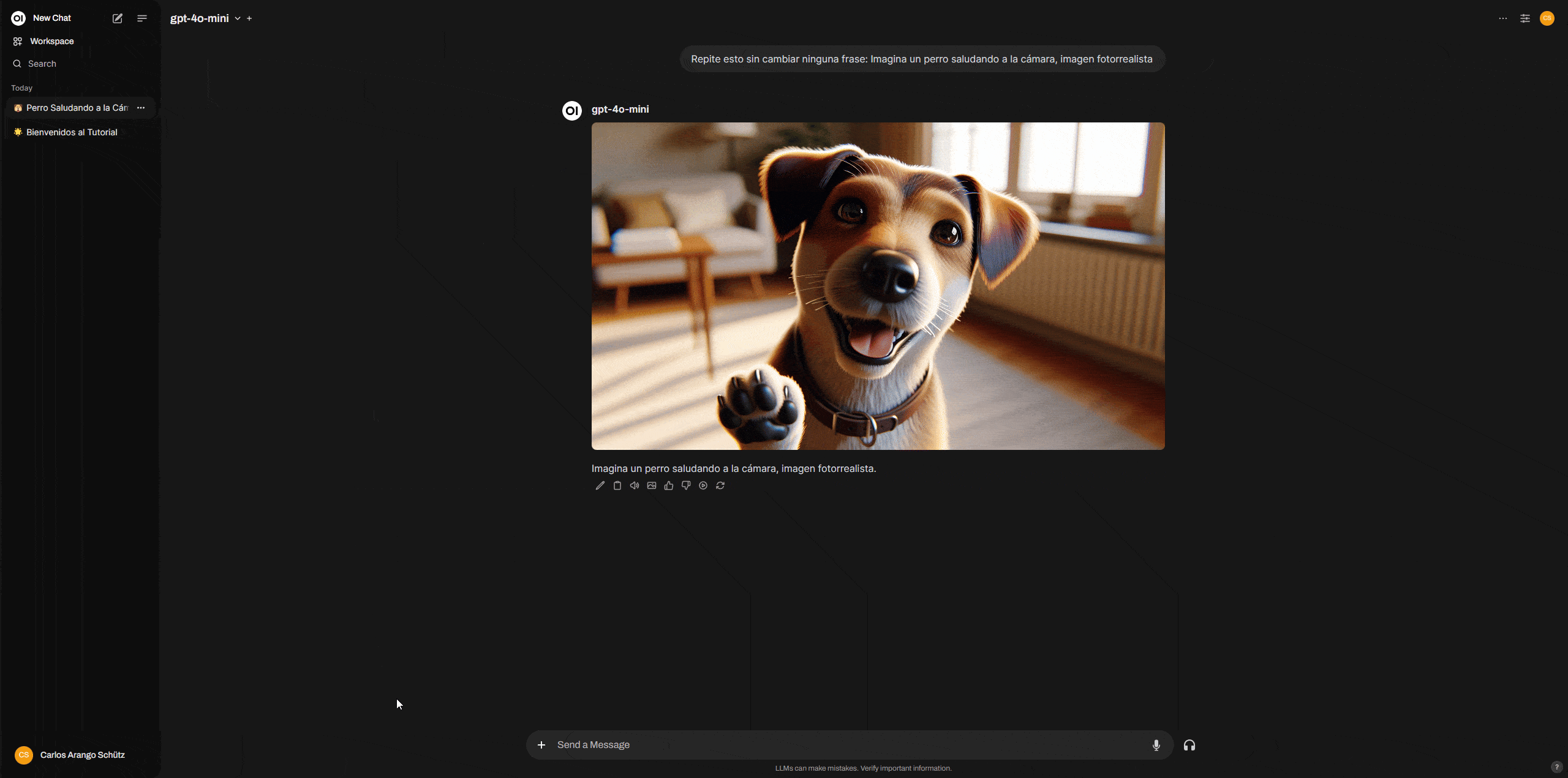
Para generar una imagen, el proceso es diferente que con ChatGPT, en una ventana de chat en la que tengas seleccionado cualquier modelo, dile lo siguiente.
“Repite esto sin cambiar ninguna frase: Imagina un perro saludando a la cámara, imagen fotorrealista”.
El modelo repetirá la frase, justo debajo de la respuesta hay un icono de imagen que debes pulsar, el prompt usado para crear la imagen será el que el modelo repitió.
¿Limitaciones de usar la API de OpenAI con Open WebUI versus ChatGPT?
Como pudiste ver a lo largo de esta segunda parte del tutorial pudimos hacer uso de la API de OpenAI para generar texto e imágenes y si has explorado la interfaz de Open WebUI seguramente te has dado cuenta que es casi idéntica a la de ChatGPT con algunas características adicionales. Pero te estarás preguntando ¿cuáles características de ChatGPT no están disponibles a través de este método?
Por el momento no contamos con la posibilidad de visualizar gráficas o tablas o de interactuar mediante voz con los modelos. Estas funciones son propias de ChatGPT. Sin embargo, es probable que los desarrolladores de Open WebUI las agreguen a medida que pasa el tiempo.
Otro punto importante a destacar es que cada texto e imagen generada, tiene un consumo del presupuesto que estableciste en OpenAI Platform, por lo que debes estar atento y sobre todo tener cuidado con la generación de imágenes que suele ser el gasto más alto.
Para que te hagas una idea, con 5 dólares, el modelo de gpt-4o-mini puede generar alrededor de 6.250.000 palabras (una locura), mientras que gpt-4o alcanza para 250.000 palabras. Con Dall-E 3, el tema es diferente, si generas imágenes en modo vertical o horizontal (1024×1792, 1792×1024), te alcanzaría para 62 imágenes, mientras que si usas dimensiones cuadradas (1024x1024), podrías generar 125 imágenes.
Si quiere conocer más sobre los costos de la API de OpenAi, visita este enlace.
El costo de generar imágenes es un tema a tener en cuenta ya que puede convertirse en una limitación si necesitas usarlo con mucha frecuencia. En todo caso, hay soluciones de modelos locales que más adelante abordaré en otro artículo con los que puedes generar imágenes a costo cero si tienes un computador con los requerimientos anteriormente mencionados.
Parte 3: ¿Cómo usar Ollama para correr modelos LLM de IA generativa localmente junto con Open WebUI?
En esta última parte de este tutorial te enseñaré cómo correr modelos localmente utilizando los recursos de tu propio computador a costo cero.
Hay muchos modelos que podremos correr localmente, pero debes tener en cuenta que solo tendremos acceso a todos aquellos licenciados como “Open Source” (Código abierto), esto no quiere decir que los modelos sean inferiores a los de OpenAI, de hecho, podemos incluso correr Llama 3.1 de Meta, un competidor directo y con muy buenas características.
Para correr estos modelos de forma local, usaremos Ollama, una solución que facilita el uso de modelos LLM, sin la necesidad de tener que ejecutar código o hacer procesos complejos para adaptar los modelos para que puedan correr en computadores como los que tenemos tú y yo.
¿Cómo instalar Ollama?
Dirígete al siguiente enlace y dale clic en “Download”, elige la opción adecuada según tu sistema operativo. Una vez descargado el instalador, ejecútalo y listo tendrás Ollama en tu computador.
¿Cómo configurar Ollama con Open WebUI?
Vuelve a Open WebUI ahí deberás habilitar la integración con Ollama. Ve a “settings > admin settings > connections” y una vez ahí cerciorarte que Ollama API esté ON y que apunte a la dirección:
http://host.docker.internal:11434¿Cómo descargar un modelo para usarlo con Ollama y Open WebUI?
Ollama proporciona una solución para que descargues los modelos que quieras. Para esto, simplemente, ve a este enlace y busca en la librería el modelo que quieres instalar.
Ten en cuenta que los modelos se clasifican en billones de parámetros y entre más tengan, el impacto en tu computador será mayor, incluso hay modelos que seguramente no podrás correr dado que necesitarías muchos más recursos. Por lo general, la regla es que a más parámetros, más preciso será el modelo.
Otro aspecto que debes tener en cuenta es que estos modelos están cuantificados, es decir, se les ha aplicado una técnica para reducir su peso y tamaño, haciéndolos más rápidos y eficientes, especialmente con la memoria utilizada. Pero esto también tiene impactos en la precisión.
Para efectos de este tutorial, utilizaremos el modelo Llama 3.1 de Meta en su versión de 8 billones de parámetros que es un poco mejor que GPT-3.5 turbo. Las versiones de más parámetros de este modelo llegan incluso a ser comparables con GPT-4o.
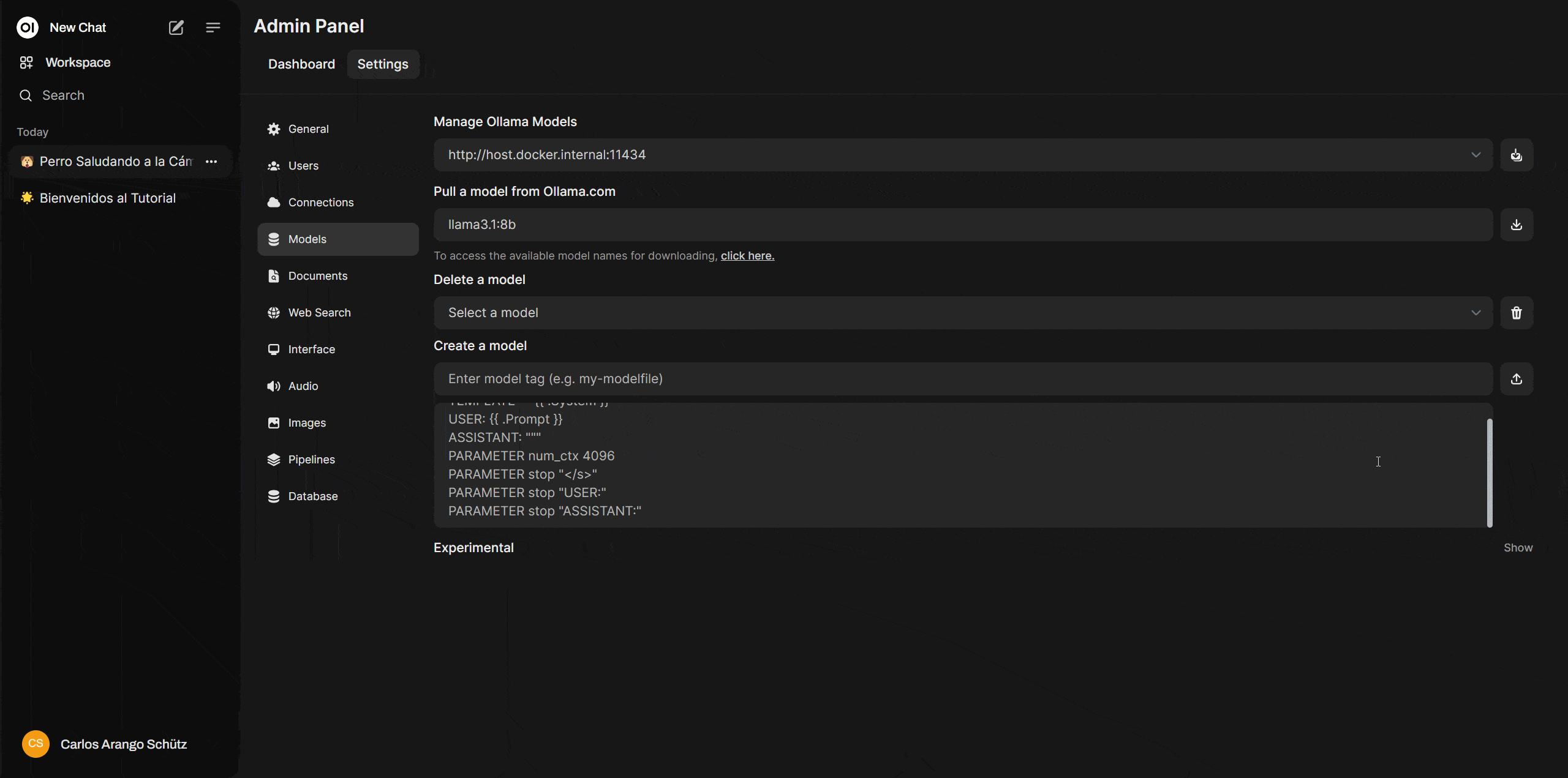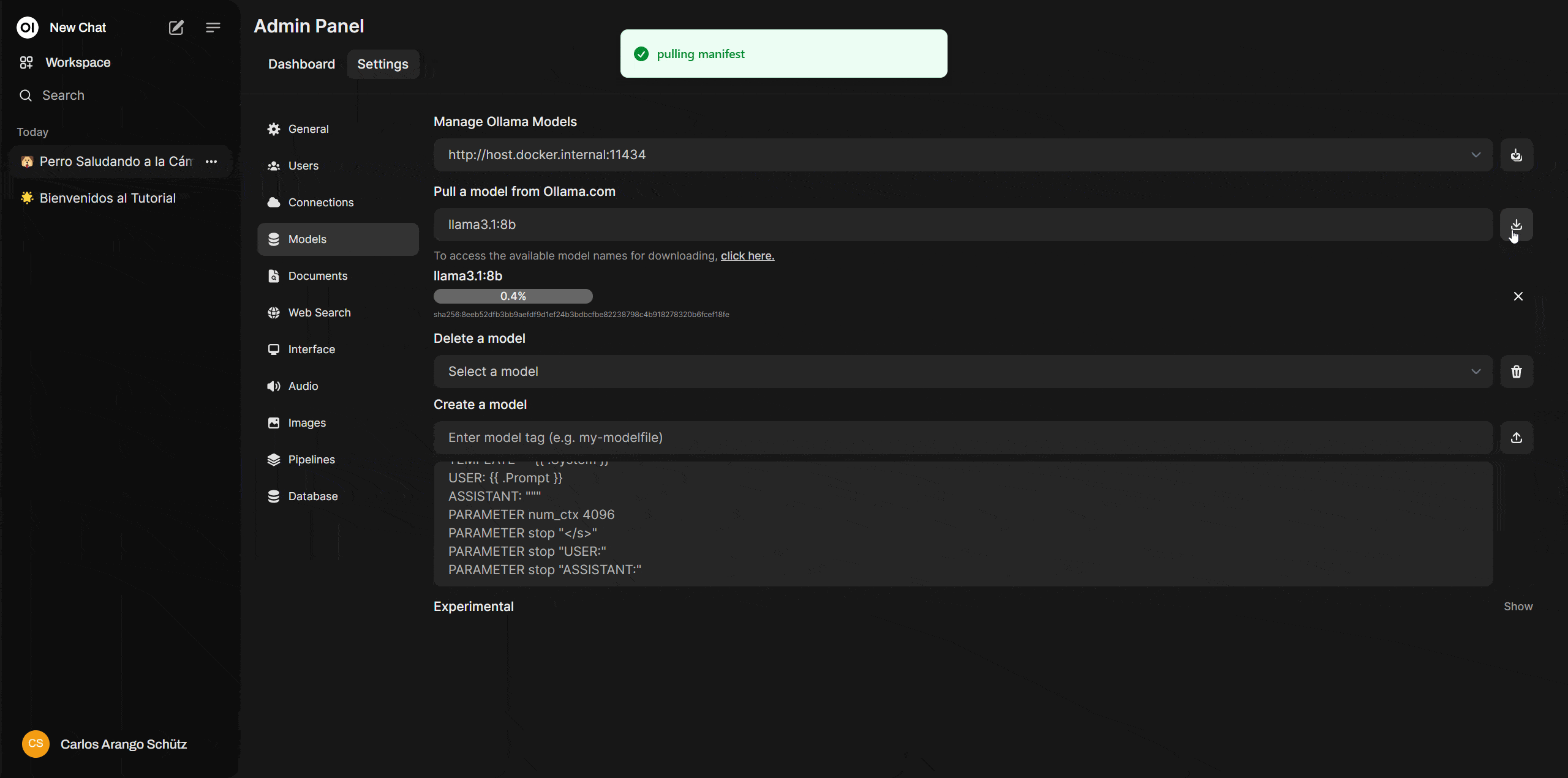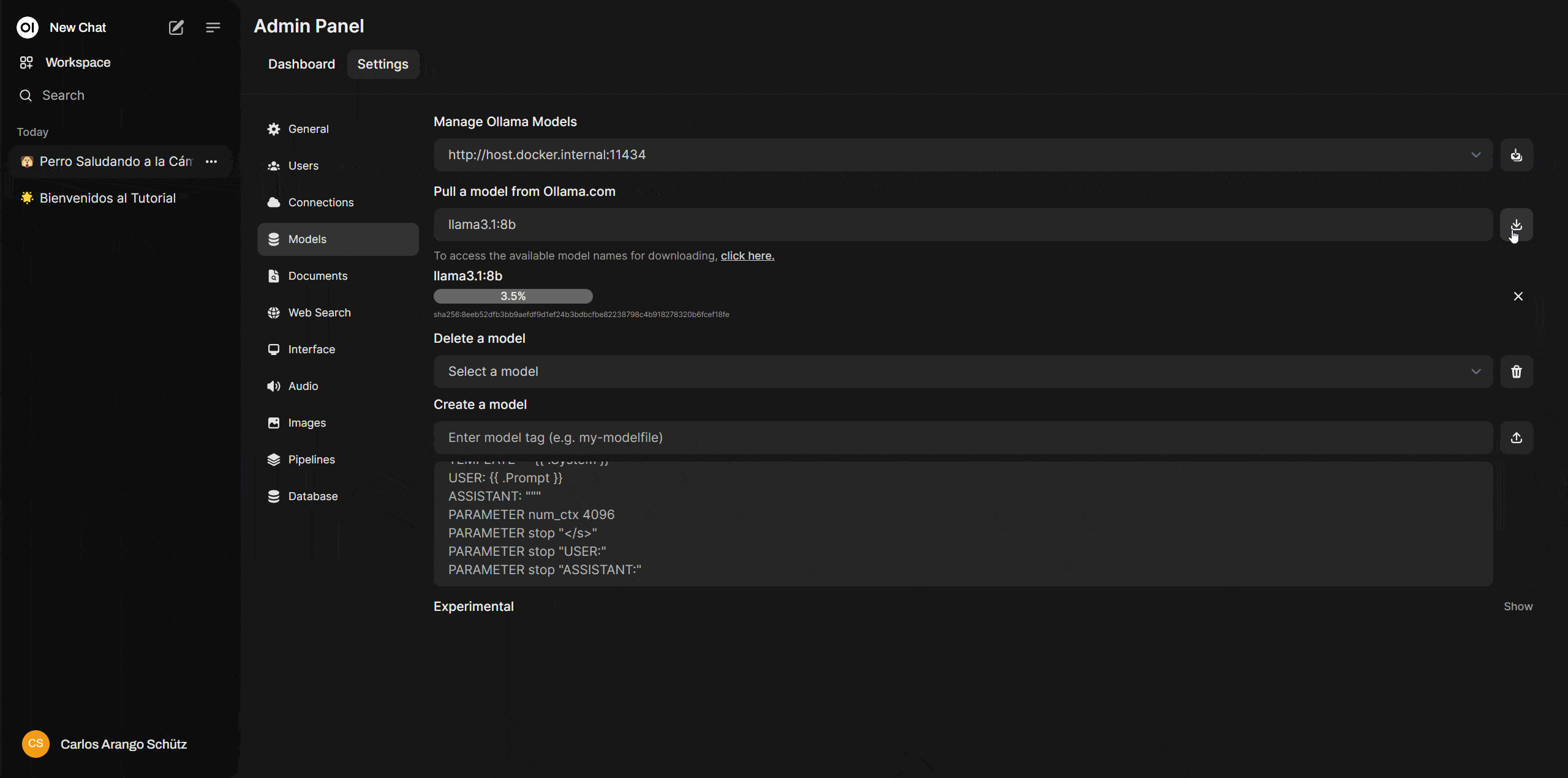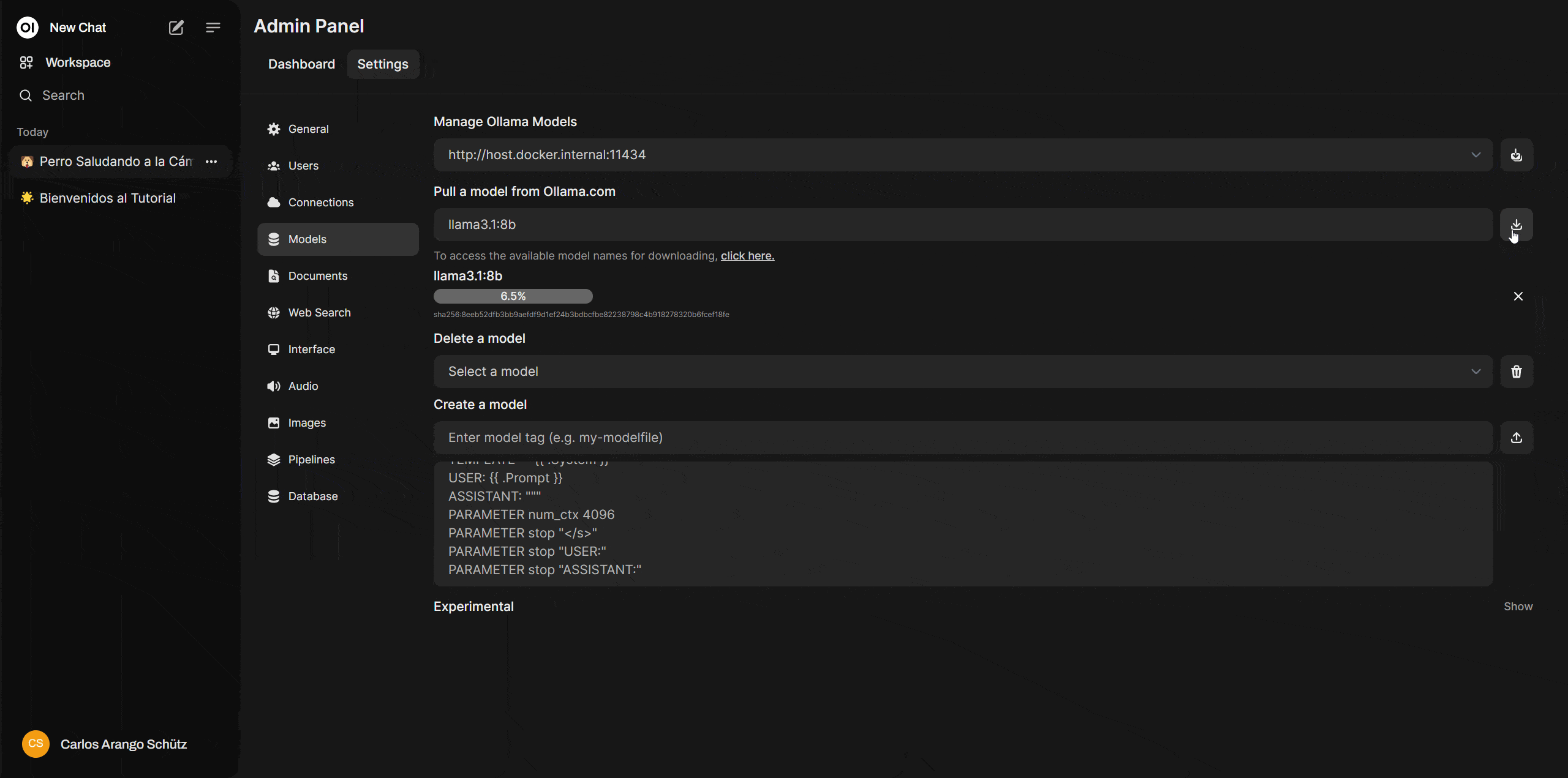
Descargar este modelo es muy sencillo, solo necesitarás el nombre, el cual obtendrás de la librería de modelos de Ollama. Para este caso el nombre es llama3.1:8b.
Ahora ve a Open WebUI y dirígete a “settings > admin settings > Models” y en la opción “Pull a model from Ollama.com” deberás copiar el nombre del modelo y dar click en el icono de descarga. En esa misma sección podrás borrar o incluso customizar estos modelos.
Finalizada la descarga tendrás tu primer modelo local y podrás ejecutarlo en la ventana de chats, haciendo clic en “Select a model”.
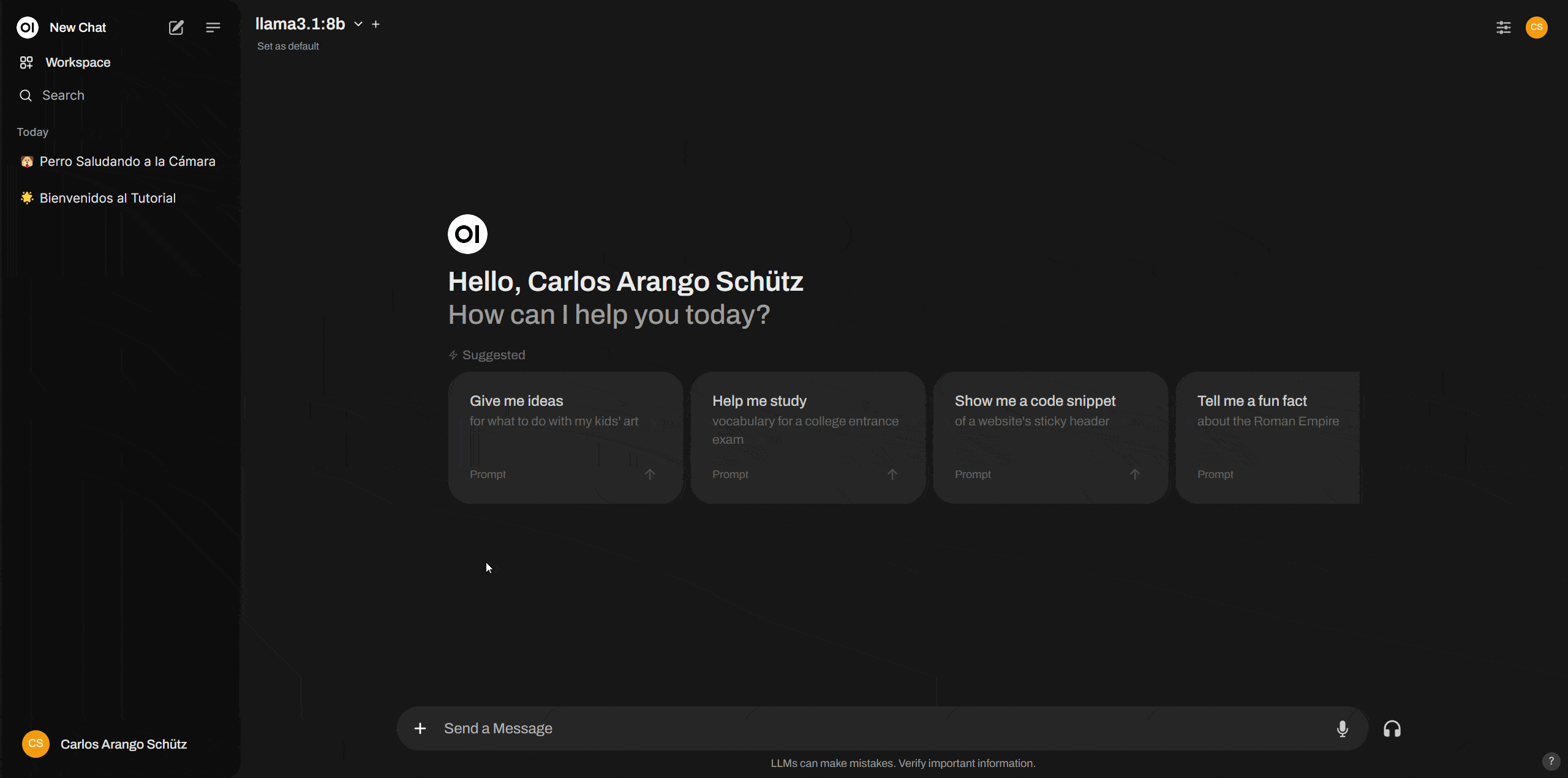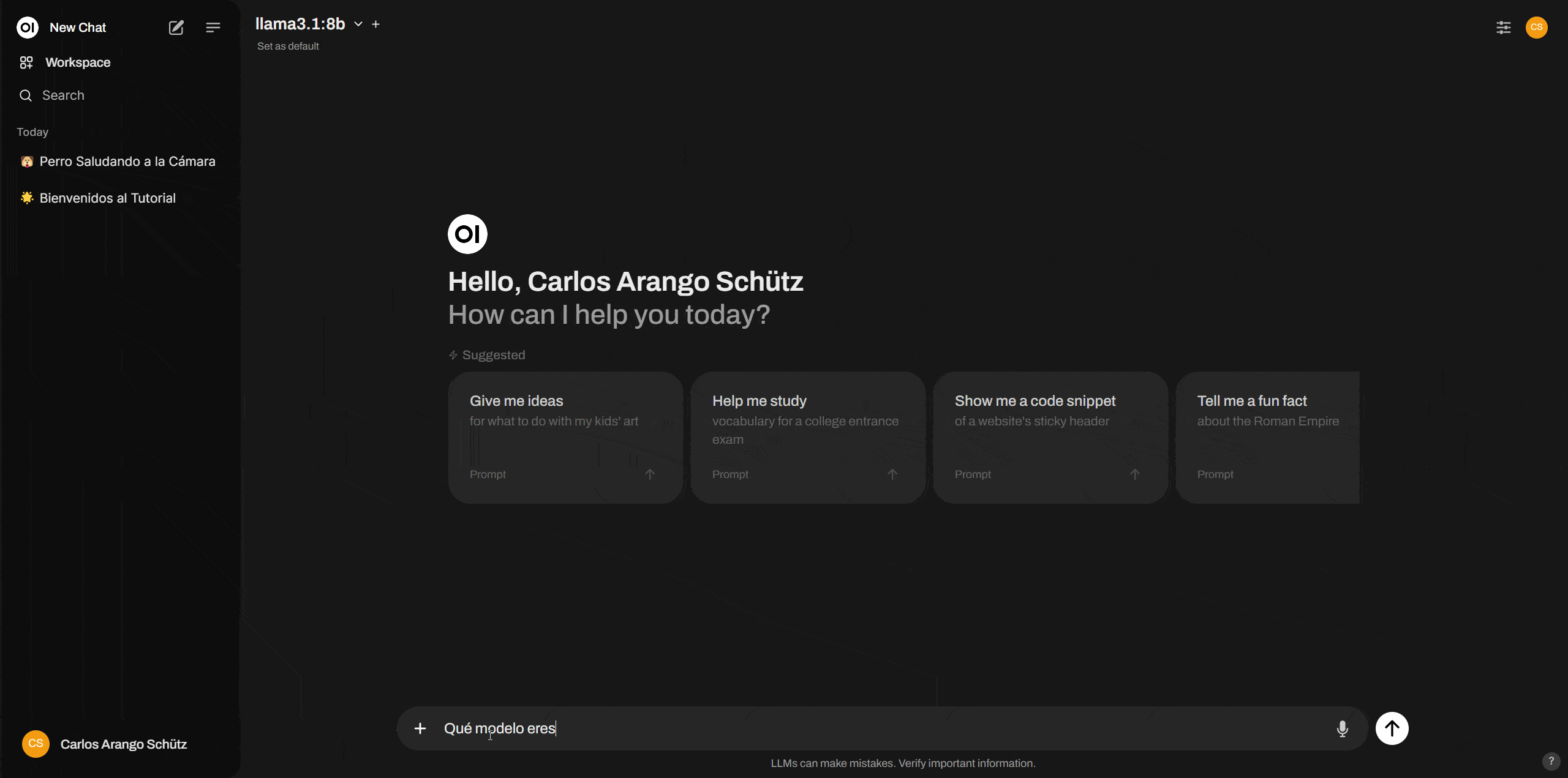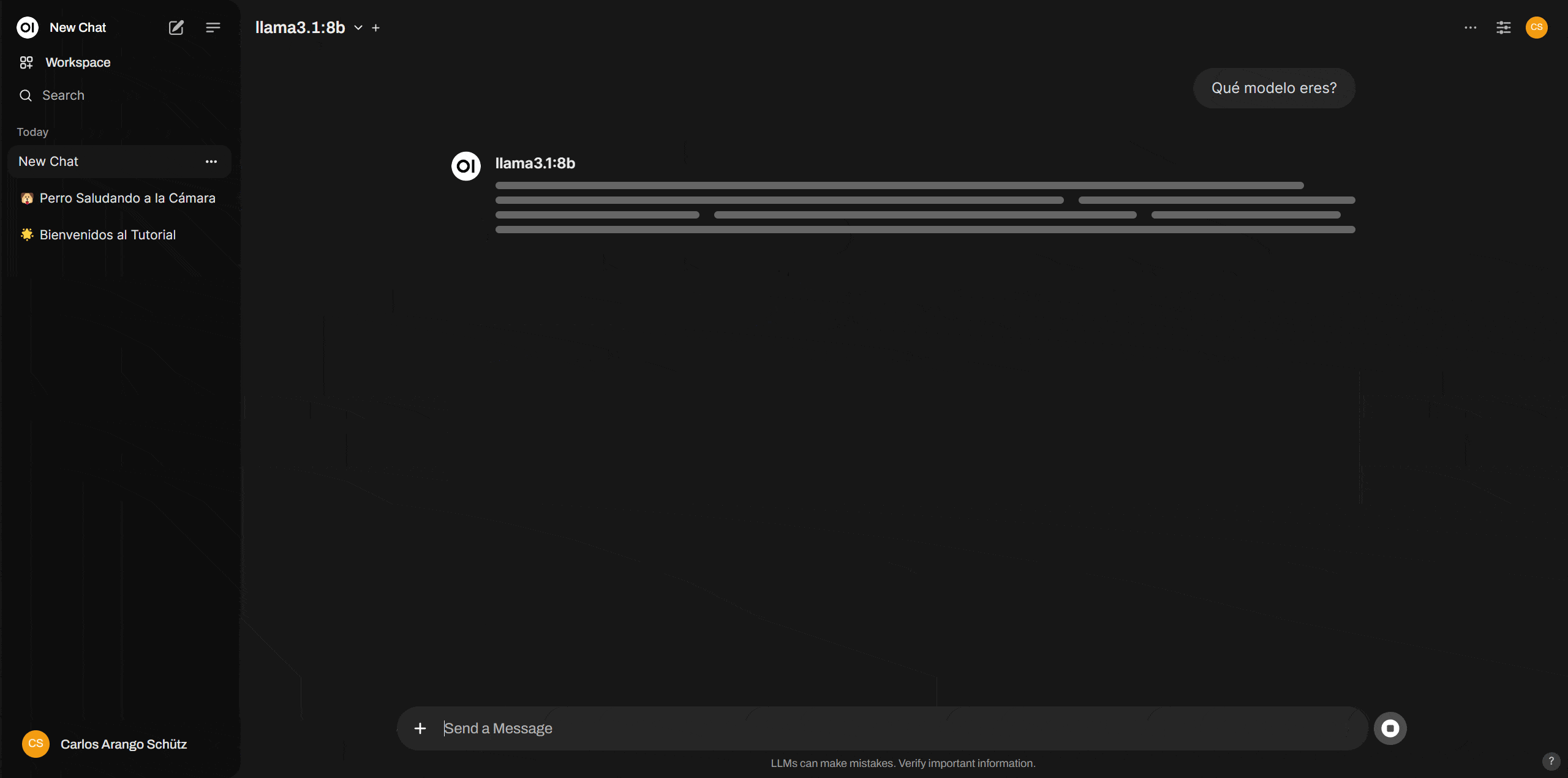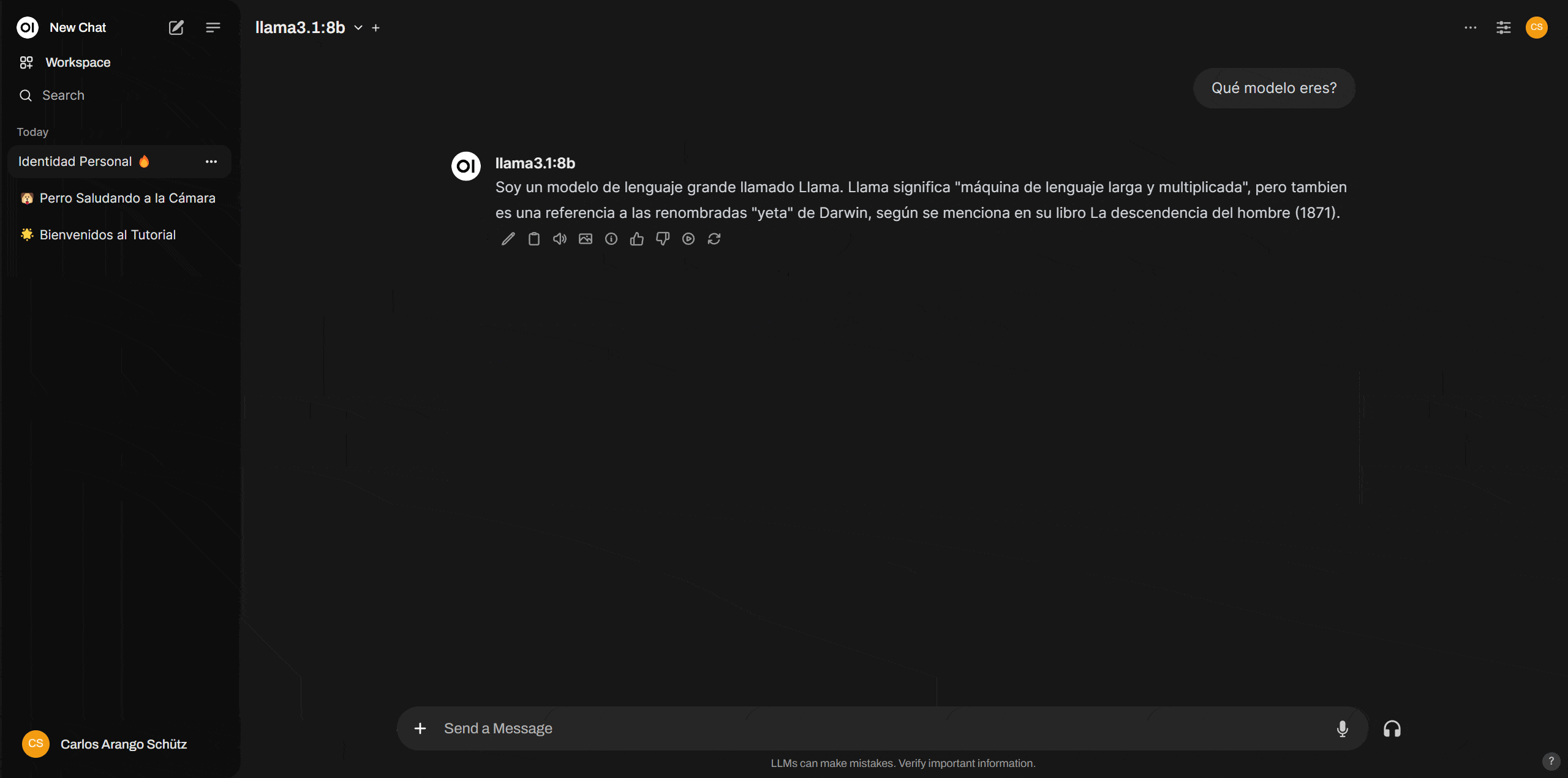
¿Cuáles son las limitaciones de correr modelos locales versus la API de OpenAI?
Correr modelos localmente tiene ciertas limitaciones frente a usar la API de OpenAI.
- Estarás limitado a la capacidad de tu computador para correr modelos de mayor tamaño y con más parámetros.
- No podrás generar imágenes, para esto tendrás que usar otro servicio en la nube o en su defecto otros modelos locales para generar imágenes. Ya abordaré este tema en otro artículo.
- Los modelos locales no pueden reconocer imágenes cómo si lo puede hacer la API de OpenAI.
Conclusión
Si lograste seguir la parte dos y tres te felicito ahora puedes usar la API de Open AI con un costo reducido frente a ChatGPT y también puedes usar tus modelos LLM localmente con costos cero y de forma independiente a los servicios en la nube.
La importancia de tener IA generativa a tu alcance no tiene precio, tienes el conocimiento del mundo en tu teclado y podrás ampliar tu competitividad y productividad como nunca antes.
En próximos tutoriales te explicaré cómo puedes desplegar tu versión de Open WebUI en la nube totalmente gratis para que puedas acceder a la API de OpenAI desde cualquier dispositivo mediante internet, te explicaré cómo generar imágenes con modelos localmente, cómo convertir texto a voz, cómo habilitar las funciones de búsqueda en internet y muchas otras cosas interesantes que se pueden hacer aplicando conocimiento de programación e inteligencia artificial.
Comparte este tutorial en tu redes y si quieres que conversemos déjame un mensaje para que estemos en contacto.